LLM Ops
Published on:

The Bottleneck in LLM Cost Optimization
If you want to know why enterprise AI spend is spiraling out of control, look at your evaluation bottleneck.
Engineering teams default to massive, expensive models like GPT-5.5 or Claude Opus 4.7 for everything. They don't do this because basic text summarization actually requires state-of-the-art reasoning. They do it because proving a smaller, cheaper model works takes too much time.
Testing an alternative model historically requires setting up an AI gateway, integrating an SDK, writing custom evaluation scripts, and wrangling datasets. When the friction to test a cheaper model is higher than the immediate cost of just using the premium one, teams choose the premium one every time.
To bring AI costs down, model evaluation has to be frictionless. It needs to be accessible not just to ML engineers, but to the FinOps practitioners and product managers responsible for the bottom line.
Let's look at how the industry has traditionally handled this, and why the AI FinOps approach requires a radically simpler workflow.
The AI Gateway Approach: Powerful, but Heavy
Tools like Braintrust, Helicone, and Portkey have established themselves as strong players in the LLM Ops and observability space. They are built to trace requests, log inputs, and monitor latency in production.
However, when it comes to rapid, exploratory model evaluation, their developer-first architecture becomes a liability.
If you look at the documentation for running structured output evals in Portkeyo r setting up playgrounds in Braintrust, a pattern emerges. You are usually required to:
Wrap your existing LLM calls in their proprietary SDK.
Define custom evaluator classes in Python or TypeScript.
Upload CSV or JSON datasets to their cloud.
Run CLI commands to generate comparison scores.
This is an excellent workflow for automated CI/CD regression testing. But it is a terrible workflow for a quick "vibe check."
If a FinOps manager sees a massive spike in OpenAI spend from an internal support bot and wants to know if a cheaper Gemini Flash model could handle the same prompts, they shouldn't have to submit a Jira ticket to engineering to build an eval pipeline.
The Cloudidr Approach: Instant, Visual Intuition
Cloudidr was built on a different premise: AI FinOps requires immediate cost visibility and actionable budget governance. To achieve that, model evaluation must be democratized.
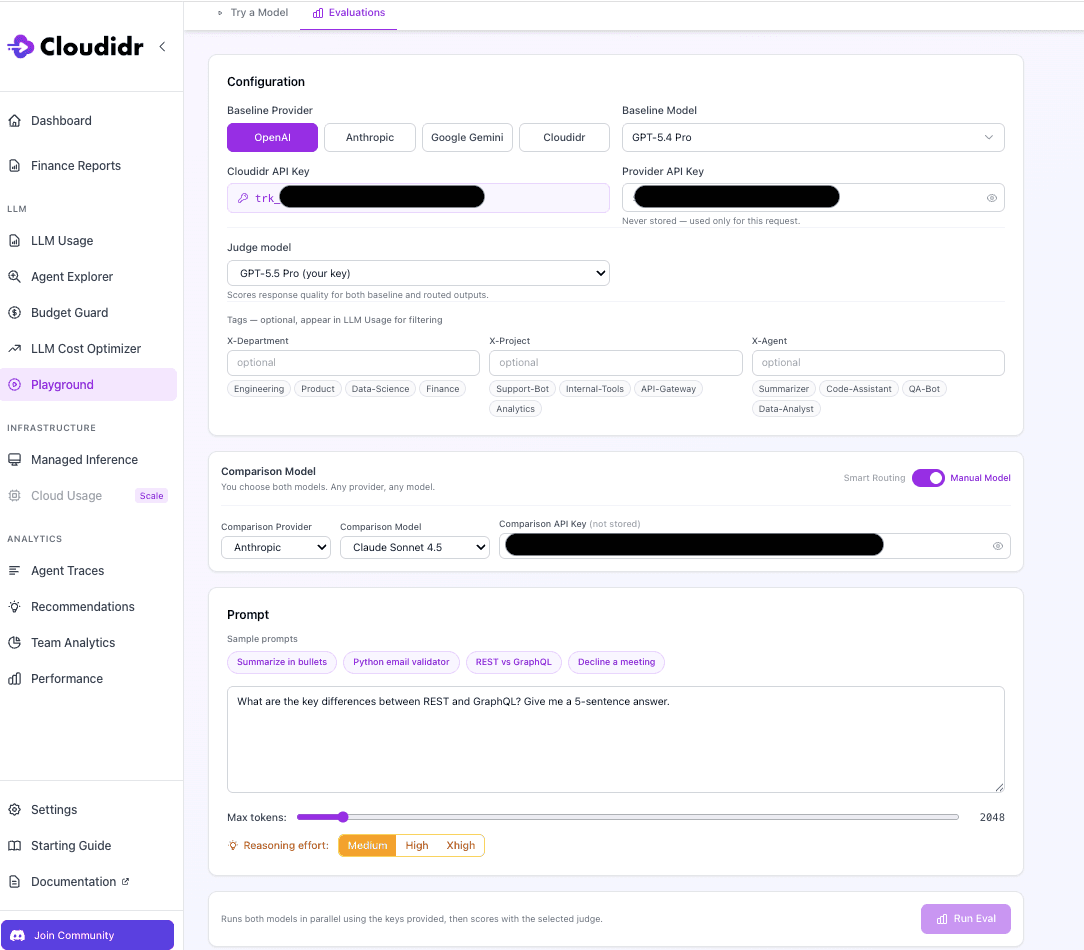
The Cloudidr Playground strips away the SDKs, the custom Python scripts, and the CLI commands. Instead, it provides a visual interface designed to build intuition rapidly.
Here is how a practitioner tests a prompt in Cloudidr:
Set the Baseline: Select your current expensive model (e.g., GPT-5.4) and drop in your prompt.
Set the Comparison: Choose a specific alternative (e.g., Claude Haiku) or toggle Smart Routing to let Cloudidr automatically select the cheapest capable substitute.
Pick a Judge: Select an LLM-as-a-judge (like the free Gemma or a frontier model) to score the outputs.
Run Eval: Paste your API keys (which are never stored, maintaining your direct provider relationships and discounts) and hit run.
In seconds, without altering a single line of your application architecture, you get a side-by-side comparison.
Hard Metrics to Replace the "Vibe Check"
When the evaluation completes, Cloudidr doesn't just give you two blocks of text to read. It gives you the operational metrics required to make an immediate engineering or financial decision.
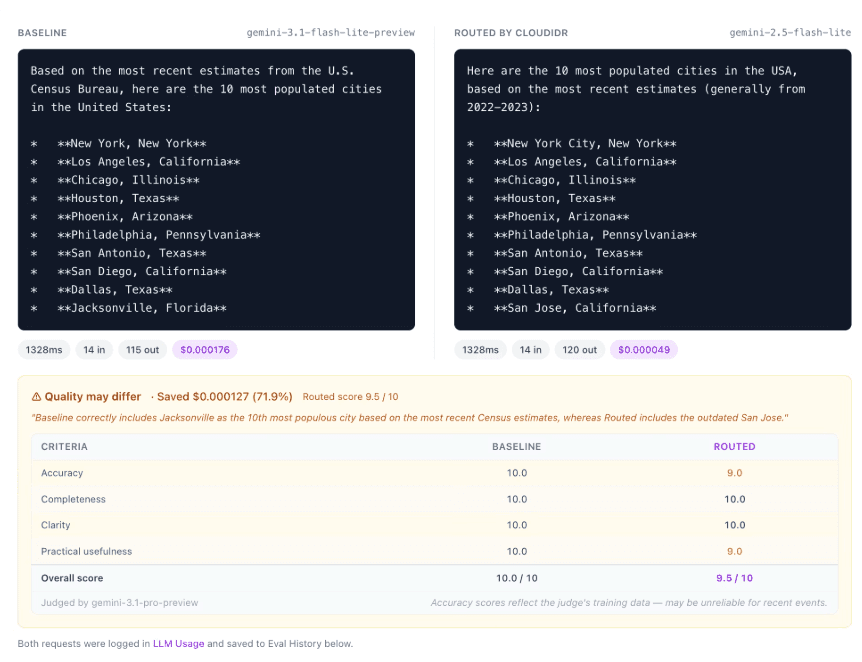
You immediately see the true cost difference per request. You see the latency delta. Most importantly, you see the judge's scoring criteria broken down by Accuracy, Completeness, Clarity, and Practical Usefulness.
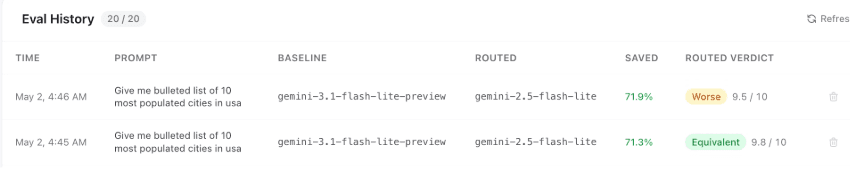
If the baseline model costs $0.000176 per request and the routed model costs $0.000049, while maintaining a 9.5/10 accuracy score, you have just found a 72% cost reduction with zero drop in practical quality. Further, Cloudier keeps Eval history for future analysis.
According toGartner's 2024 research, managing the cost and trust of AI deployments is the primary barrier to scaling Generative AI. Visual, deterministic evaluations are how you bridge that gap. You replace assumptions with hard data.
From Evaluation to Actionable Routing
The fundamental difference between observability platforms and an AI FinOps platform is actionability.
Helicone and Portkey will tell you that you are spending too much on OpenAI. Braintrust will help your engineers test a prompt against a dataset.
But Cloudidr actually executes the savings.
Once you use the Playground to prove that a cheaper model can handle a specific workload, you don't need to go rewrite your application logic to implement the change. Cloudidr's intelligent model routing engine handles it dynamically.
By integrating Cloudidr via a 60-second, two-line code change, you plug your infrastructure into a routing control plane. Cloudidr intercepts requests in real time and routes them to the cheapest capable model across OpenAI, Anthropic, Google Gemini, and AWS Bedrock. It adds less than 40ms of latency and requires absolutely no architecture changes on your end.
In enterprise environments, this translates to massive impact. In a recent healthcare benchmark across clinical summarization workloads, Cloudidr's intelligent routing achieved roughly $83K saved per $100K of baseline LLM spend, all while maintaining clinical quality standards verified by these exact evaluation mechanics.
Stop Guessing, Start Routing
Evaluating LLMs shouldn't require a dedicated sprint. If your team is stuck in a cycle of over-provisioning because testing alternatives is too hard, your tooling is failing you.
Leave the complex, code-heavy CI/CD regression suites to the observability tools. When you need rapid, intuitive model evaluation that leads directly to hard budget controls and up to 90% cost savings, you need an AI FinOps platform.
Take 60 seconds to visualize your potential savings. Try the Cloudidr Evaluation Playground today and see exactly how much you are overpaying for your current LLM workloads.





