LLM Ops
Published on:
Khursheed Hassan, Founder & CEO, Cloudidr
We've Seen This Movie Before
By 2012, AWS bills were becoming a mystery. Teams were spinning up EC2 instances, S3 buckets, and RDS clusters faster than finance could track. By the time the monthly invoice arrived, the damage was done — steep cloud bills with no clear owner, no visibility into what was driving them, and no automated way to fix it.
The industry responded by inventing Cloud FinOps: tagging policies, cost allocation by team, reserved instance optimization, rightsizing recommendations. A whole ecosystem emerged — CloudHealth, Apptio, AWS Cost Explorer, Spot.io. Gartner made it a category. FinOps Foundation made it a certification.
Today, the same pattern is playing out again — but the medium has changed from compute to intelligence, the pace is 3x times faster, and the tooling gap is even wider.
AI teams are making millions of API calls per day across OpenAI, Anthropic, Google, and their own GPU infrastructure. Finance gets a bill. Engineering can't explain it. Nobody knows which agent, team, or workload is responsible. And nobody is confident they're using the right model for each task.
This is the AI FinOps problem. And here's the critical distinction that matters for anyone thinking about the market: it is not a problem Cloud FinOps companies can solve.
Why Cloud FinOps Companies Are the Wrong Tool for This Problem
I often get the question whether existing cloud FinOps companies can solve this as addendum. I will try to answer it here both for the practitioners and for investors evaluating the space. When Apptio, Datadog, or CloudHealth adds an "AI spend" tab to their dashboard, it looks like they're entering the AI cost management market. They are not. Here's why.
Cloud FinOps is fundamentally an inventory tagging and reservation optimization problem.
The entire Cloud FinOps stack is built on a specific data model: resource IDs, usage hours, commitment tiers, and tagging taxonomies. The optimization actions are inventory-level: buy reserved instances, rightsize over-provisioned EC2 instances, move cold data to cheaper S3 tiers, tag untagged resources so they can be attributed to a cost center.
These tools are excellent at what they were designed to do. But AI cost optimization is an entirely different class of problem.
AI FinOps is a semantic routing problem.
To optimize AI costs, you need to understand the content of each request — its complexity, its required quality threshold, its latency sensitivity — and match it to the right model from a portfolio where pricing varies by 250x. That is not an inventory problem. That is a per-request intelligence problem.
No Cloud FinOps tool has any concept of:
Token economics — the asymmetric relationship between input and output token costs
Prompt complexity scoring — classifying each incoming request to determine which model tier it warrants
Model capability tiers — knowing that a simple FAQ doesn't need Claude Opus 4.6, but a multi-document legal analysis does
Quality thresholds — setting minimum acceptable output quality per use case and routing accordingly
Real-time per-request routing — making a model selection decision in milliseconds, on every single API call
A Cloud FinOps platform adding an "AI spend" module can show you how much you spent on OpenAI last month, broken down by team. That is the equivalent of a fuel gauge. It tells you how much fuel you burned. It does not make the engine more efficient.
Our own ground up designed LLM Ops platform is the engine optimization layer - honed to solve this problem space. It doesn't just report on AI spend — it actively reduces it, automatically, on every request, without any changes to application code.
The data models are incompatible. Cloud FinOps tracks resource IDs and usage hours. AI FinOps tracks tokens, models, prompt complexity scores, quality outcomes, and routing decisions. You cannot bolt one onto the other.
The optimization cadence is incompatible. Cloud FinOps recommendations are reviewed quarterly in FinOps rituals. AI cost optimization happens in real time — microseconds per decision, millions of decisions per day. There is no equivalent of a "quarterly Reserved Instance review" for LLM routing.
The optimization action is incompatible. Cloud FinOps says "buy a 3-year Reserved Instance for this EC2 type." AI FinOps says "this specific prompt, right now, should be routed to Gemini 2.5 Flash-Lite instead of Claude Sonnet 4.6, saving 94% on this request while maintaining output quality." Those are not adjacent capabilities.
This is why AI FinOps is a purpose-built category — not a feature addition to an existing platform. Cloudidr is building the infrastructure that makes AI spend optimizable at the request level. That is a fundamentally new discipline.
What Is AI FinOps?
AI FinOps is the practice of maximizing business value from AI investment through three disciplines — plus a fourth that separates best-in-class platforms from basic monitors:
Visibility — real-time insight into exactly where AI money is going, by model, provider, team, agent, and request
Budget Guardrails — proactive controls that prevent runaway costs before they happen
Intelligent Model Routing — automated per-request optimization that matches each prompt to the right model
AI-Powered Insights — proactive recommendations that surface optimization opportunities you didn't know to look for. For well designed platforms these should be automatically handled during model routing.
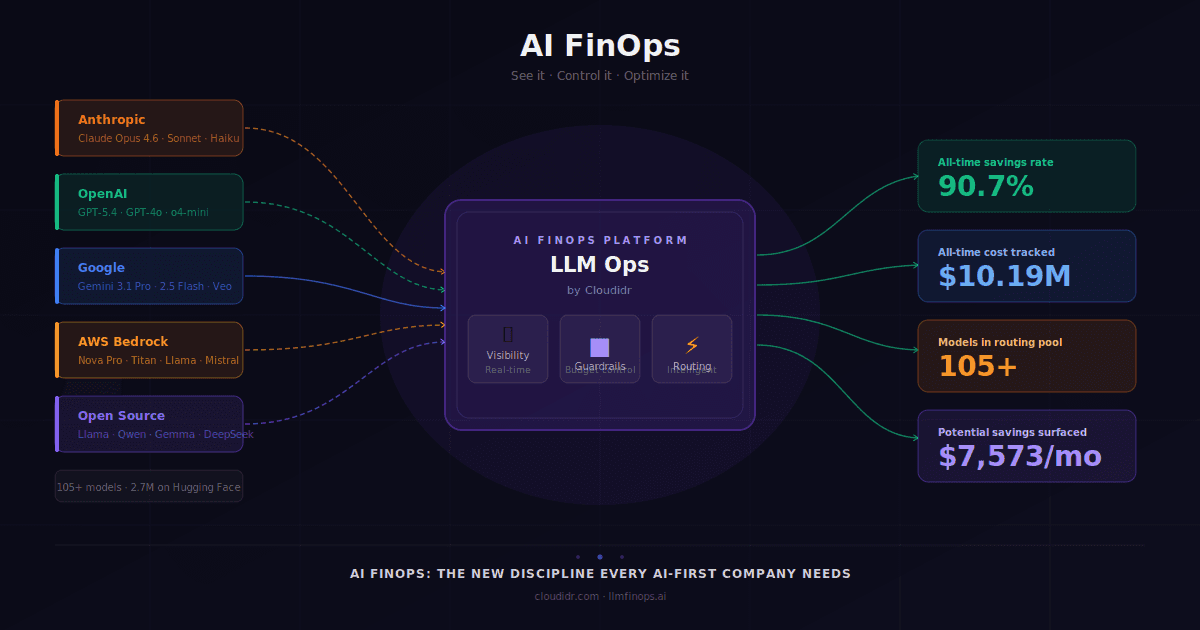
AI FinOps covers the full AI cost stack: LLM API costs (what you pay per token to OpenAI, Anthropic, and Google), GPU compute costs (what you spend to run open-source models on your own infrastructure), and cross-provider routing efficiency.
The foundational principles apply equally to agentic and non-agentic workflows. Whether you're running a simple RAG pipeline or a multi-agent system orchestrating 50 API calls per task — the same pillars apply. In fact, agentic workflows make AI FinOps more critical. A single misconfigured agent loop calling a premium model thousands of times is a five-figure bill you didn't see coming. AI FinOps is the circuit breaker.
Cloudidr is defining the AI FinOps category. Explore the platform at llmfinops.ai · Start free → · Book a demo →
Why Now? The Complexity Has Become Unmanageable
Here is the scale of the problem in April 2026:
From the three biggest providers alone — OpenAI, Anthropic, and Google — there are already 105 active models spanning text, reasoning, multimodal, audio, video, image generation, embeddings, and specialized agents. Each with different pricing, context windows, capability profiles, and deprecation timelines.
But that's just the surface.
As of April 2026, Hugging Face lists 2,786,397 models. Cloud hyperscalers — AWS, Google Cloud, Azure — are all shipping their own fine-tuned and hosted variants. Specialized vertical AI companies are releasing domain-specific models for legal, medical, finance, and code weekly. The open-source community is releasing new capable models continuously — Llama, Mistral, Qwen, Gemma, DeepSeek — many of which outperform or are close enough to commercial APIs at a fraction of the cost for specific workloads.
The result: a developer trying to pick the right model for their workload faces a bewildering range of options with no clear framework for evaluation. And the stakes are high because the pricing variance between models can be 90–95%.
A team running document processing on Claude Sonnet 4.6 at $18/M tokens total could run the same workload on Gemini 2.5 Flash at $2.80/M — an 84% cost reduction — with comparable output quality. At one billion tokens per month, that's a swing of $15,200 in monthly spend, or $182,400 annually. From a single pipeline decision that no one reviewed.
The parallel to early Cloud FinOps is precise: rapid innovation creates sprawl, sprawl creates complexity, complexity makes it impossible for development teams — who are focused on shipping product, not auditing bills — to continuously evaluate and apply the optimal model for every workload. In cloud FinOps, the answer was tooling that made optimization automatic. The same answer applies here, but the tooling must be purpose-built for the AI cost stack.
The Hidden Layer: GPU Utilization Is a Black Box
There's a second cost problem that doesn't show up on API invoices at all.
A growing number of forward-thinking companies are choosing not to send their data to third-party API providers. For reasons of data security, regulatory compliance (HIPAA, GDPR, FedRAMP), or cost efficiency at scale, these teams prefer to run open-source models — Llama, Mistral, Qwen, Gemma — on their own GPU infrastructure.
At sufficient volume, this is often the right call. Self-hosted inference can be dramatically cheaper than per-token API rates. It keeps sensitive data entirely within your security perimeter.
But it introduces a new cost opacity: GPU utilization. Most teams running self-hosted inference have no clear view of whether their GPUs are being used efficiently. Are they running at 20% utilization? Is a specific model allocation sitting idle while another is over-requested? Are cold-start latencies inflating per-query costs?
These are the GPU equivalent of "which EC2 instance is idle" — the question that launched the Cloud FinOps category in 2012. Cloudidr's GPU Usage module brings the same visibility to GPU infrastructure that we bring to API costs.
And critically — Cloudidr's managed inferencing doesn't just support self-hosted models in isolation. It enables dynamic routing between commercial provider APIs and self-hosted open-source models, letting teams capture the best economics for each workload, each compliance requirement, and each quality threshold in real time. The maximum flexibility comes not just from running open-source models, but from the ability to route intelligently across the entire model portfolio — from GPT-5.4 to Gemini 3.1 Pro to open source Qwen — within a single unified platform.
The Four Pillars of AI FinOps in Practice
Pillar 1 — Visibility: You Can't Optimize What You Can't See
The first question every AI team should be able to answer — and almost none can today — is: exactly where is our AI money going?
Not just "we spend $X on OpenAI per month." But: which department/team, which project, which agent, which model, at what cost per request, trending in which direction, and how does today's spend compare to last week?
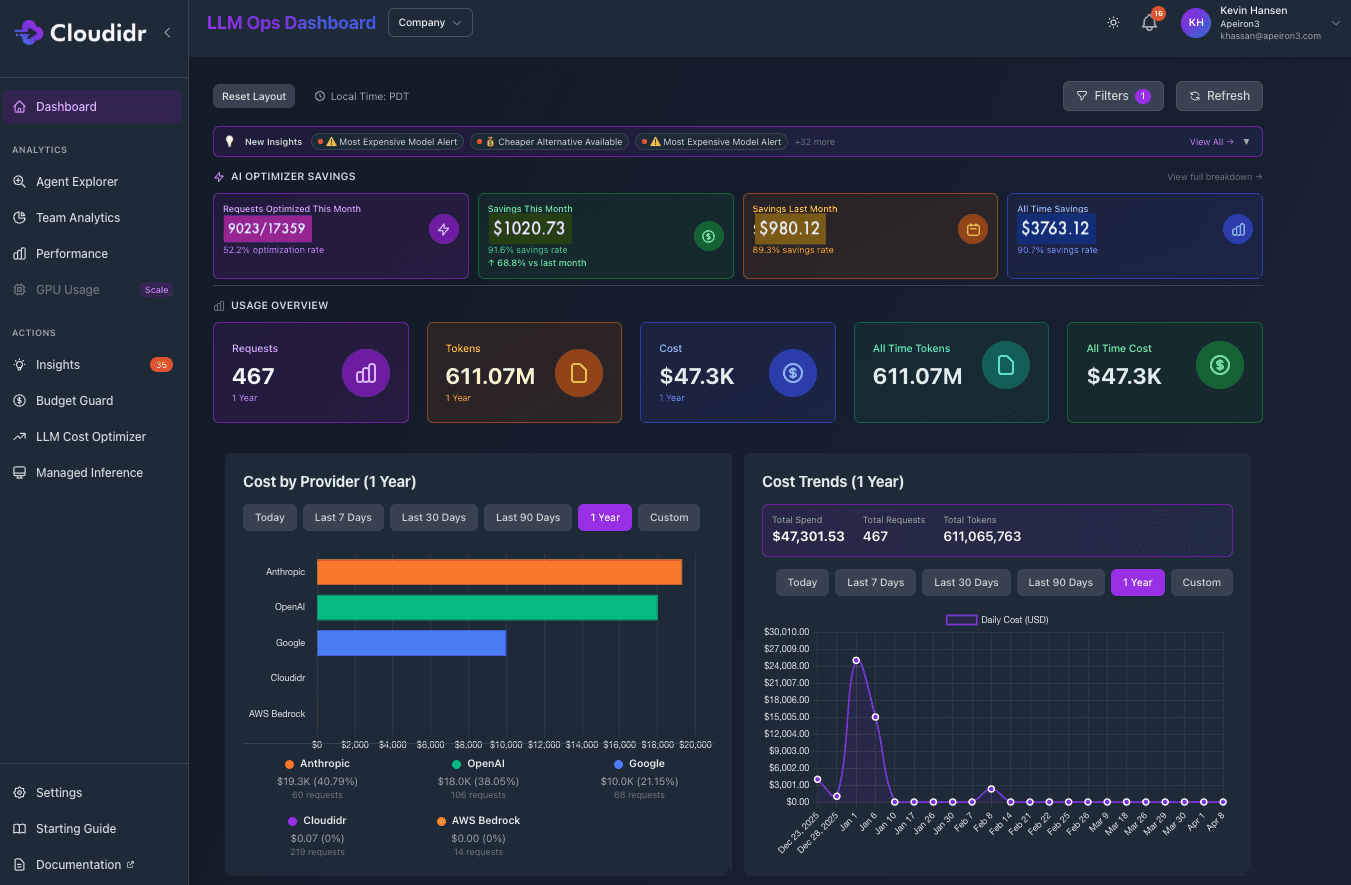
LLM Ops dashboard gives decision makers a global view of spend across providers, teams and models. This single view replaces multiple separate billing portals and a monthly finance spreadsheet. More importantly, it answers the question that every CFO is starting to ask: which business unit is driving our AI spend, and is it proportional to the value it's generating?
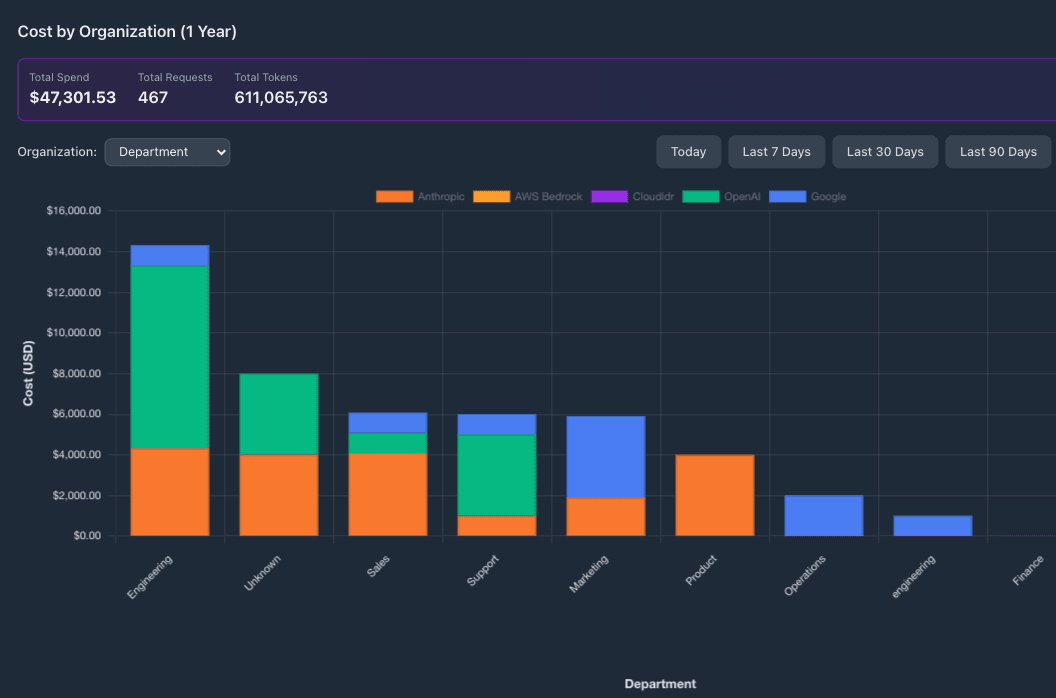
Next, the department-level analytics view shows AI spend broken down by department — Engineering, Sales, Marketing, and more — with each bar split by provider (Anthropic, OpenAI, Google). Engineering-heavy teams dominate spend, while the mix of providers varies significantly by team — revealing that different teams have organically adopted different providers without organizational visibility into the aggregate pattern.
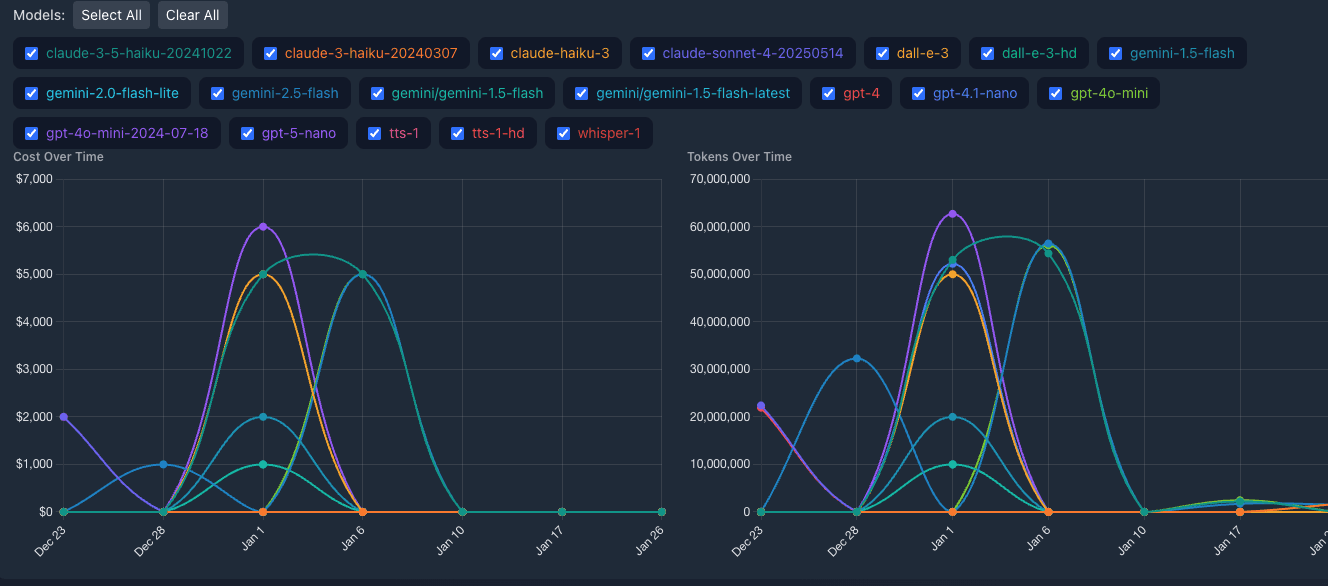
Further, the Model Usage Analysis overlays cost-over-time and tokens-over-time for every model in use simultaneously. Teams can immediately spot usage spikes, model drift, and the comparative cost trajectory of different models. This view is particularly powerful during model migrations — the cost impact of switching from one model to another is visible in real time, not discovered three weeks later.
Key visibility capabilities:
Real-time spend tracking by model, provider, department, team, project, and agent
Multi-provider consolidated view: OpenAI, Anthropic, Google, AWS Bedrock, Cloudidr (managed inference)
Token consumption and cost correlation with custom time windows
Model usage analysis with per-model trend overlays
Per-request cost attribution down to the individual agent level
Pillar 2 — Budget Guardrails: Control Before the Bill Arrives
Visibility tells you what happened. Guardrails prevent the bad thing from happening in the first place.
This is where AI FinOps diverges most sharply from traditional monitoring — and most sharply from what Cloud FinOps tools can offer. The speed at which an agentic workflow can generate cost means reactive monitoring is insufficient. You need proactive controls that enforce budget limits automatically, at the agent level, in real time.
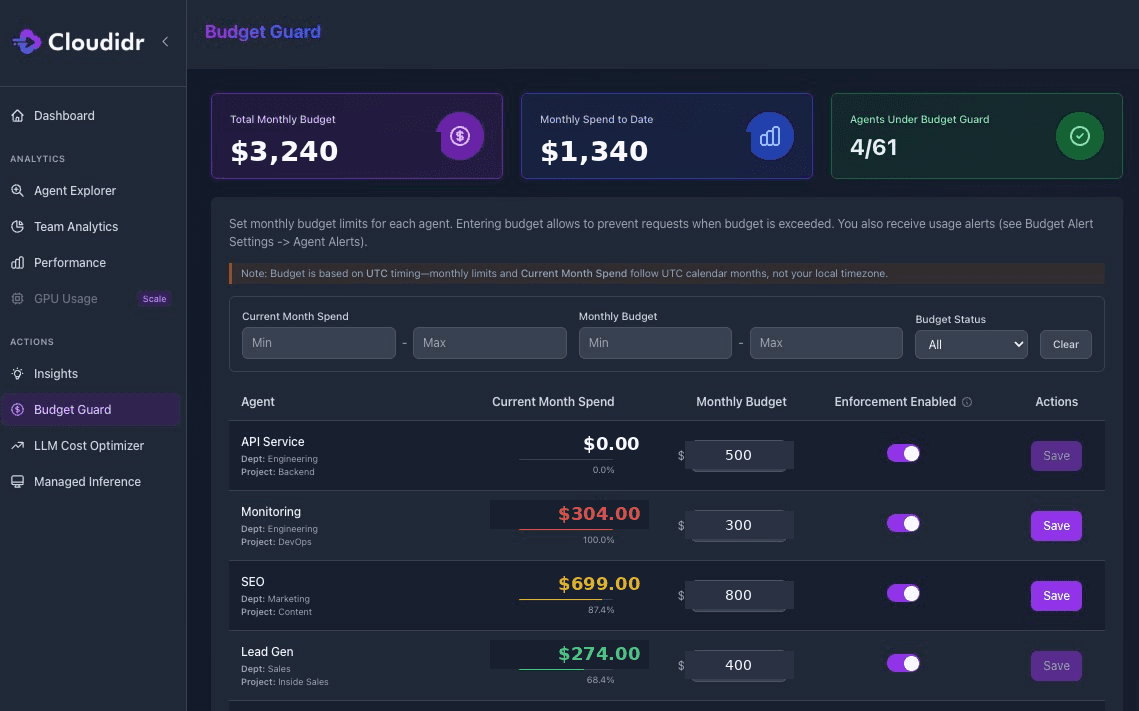
Budget Guard shows per-agent spend against monthly budget limits with color-coded progress bars. The Monitoring agent (Engineering/ DevOps) is shown in red at 100% of its $300 budget — having spent $304, it has breached its limit. The SEO agent is at 87% of its $800 budget. Budget enforcement is toggled on per-agent, meaning Cloudidr will automatically throttle or downgrade model tier for agents approaching or exceeding their limits — no human intervention required.
The red SEO agent in that screenshot is the scenario that every AI engineering team has experienced. A workload runs hotter than expected. Nobody notices until the month-end review. The bill is already $250 over budget. Budget Guard is the automated circuit breaker that makes that scenario impossible.
Why this matters for agentic workloads in particular: a multi-step agent processing a complex research task might make 40–60 LLM calls in a single run. Without per-agent budget controls, there is no ceiling. A single runaway agent in a production environment can generate thousands of dollars in unexpected spend before a human notices. Budget Guard enforces limits at the agent level, with configurable actions: alert, throttle, or automatically switch to a lower-cost model.
Key Budget Guard capabilities:
Hard and soft budget limits by org, department/team, project, and individual agent
Real-time enforcement — not monthly reviews
Automatic model downgrade when budgets are approached
Visual progress bars with color-coded status (green / amber / red)
Per-department and per-team budget allocation with enforcement toggle per agent
Pillar 3 — Intelligent Model Routing: Optimization That Acts Automatically
The third pillar is where AI FinOps becomes genuinely differentiated from everything that came before it — including Cloud FinOps. Visibility shows you the problem. Guardrails set the ceiling. Routing actively solves the problem, on every single request, automatically.
Cloudidr's LLM Cost Optimizer scores each incoming prompt for complexity and routes it to the most cost-effective model that can handle it at the required quality level. A simple FAQ lookup doesn't need Claude Opus 4.6. A complex multi-document legal analysis does. The routing engine makes that determination in real time, transparently, with no changes to application code.
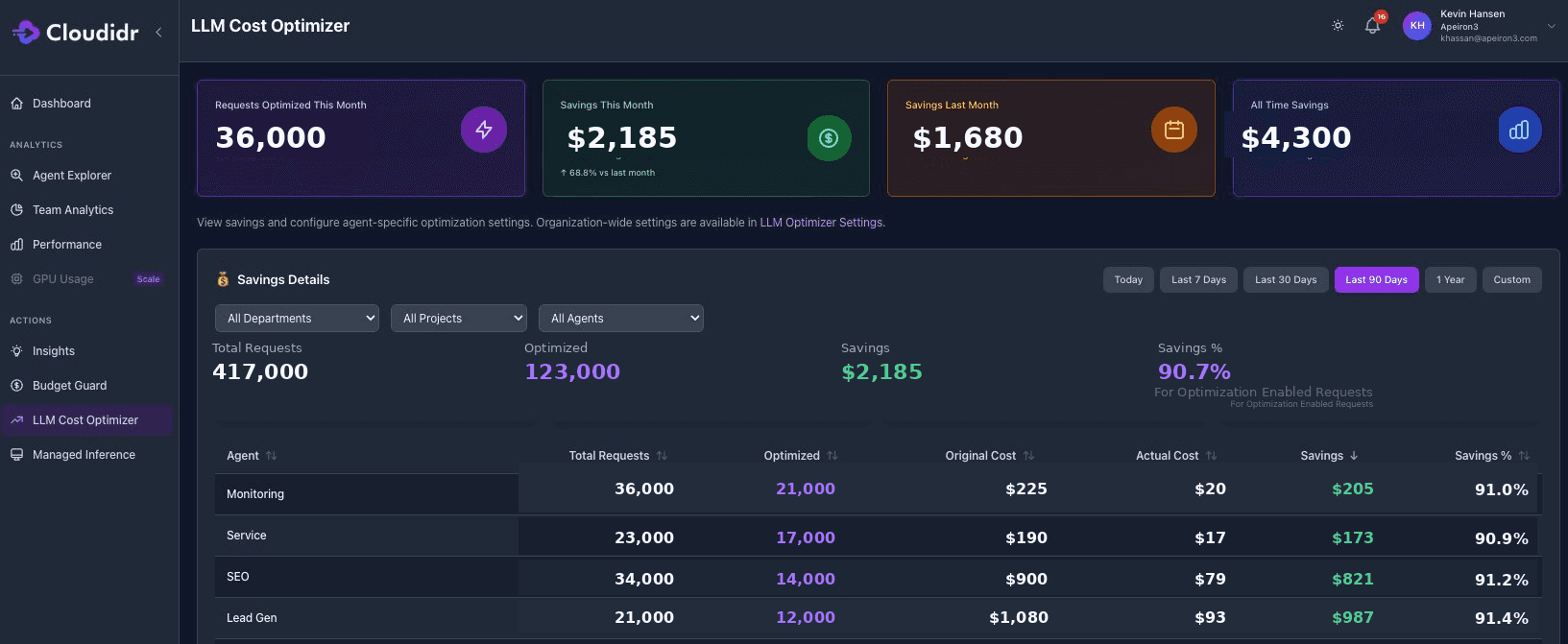
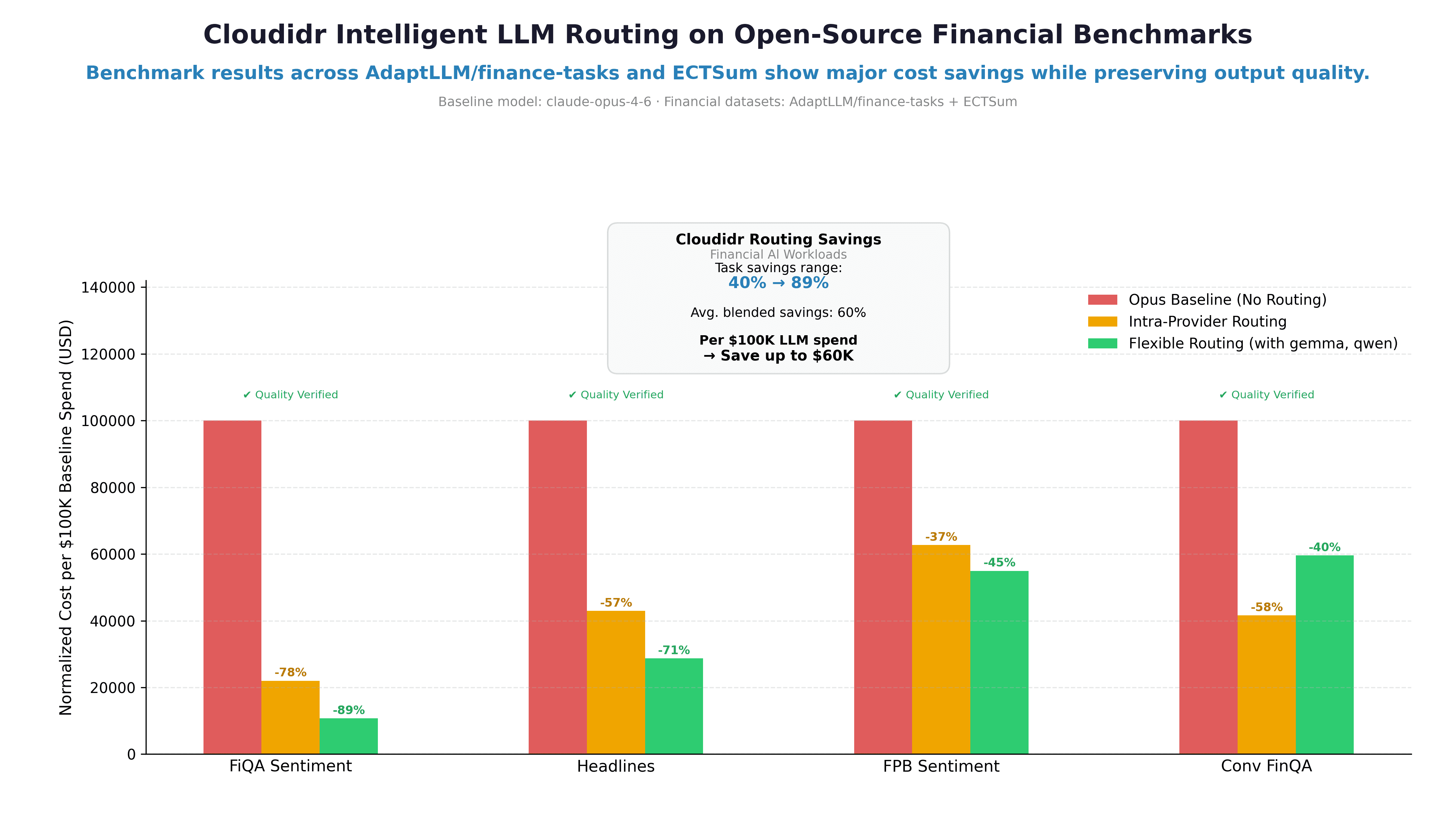
The savings rates speak for themselves: across deployments, teams consistently see 89–92% savings on optimized requests, with 52%+ of total requests qualifying for optimization. A team spending $150,000/month on LLM API costs would save approximately $70,000–$80,000 per month at those rates — $840,000–$960,000 annually — simply by letting the routing engine do what a developer team can't do manually at scale.
Key routing capabilities:
Automatic complexity scoring per prompt
Configurable model pool (which models are eligible for routing per use case)
Quality floor controls (minimum acceptable model tier per workload)
Per-agent routing policy customization
Full audit trail: routing decisions, original cost, actual cost, savings per request
Pillar 4 — AI-Powered Insights: The Recommendations You Didn't Know to Look For
The fourth pillar separates a monitoring tool from an optimization platform. Visibility, guardrails, and routing address the problems you've already identified. Insights surface the optimization opportunities you haven't found yet — proactively, with specific dollar impact and a recommended action.
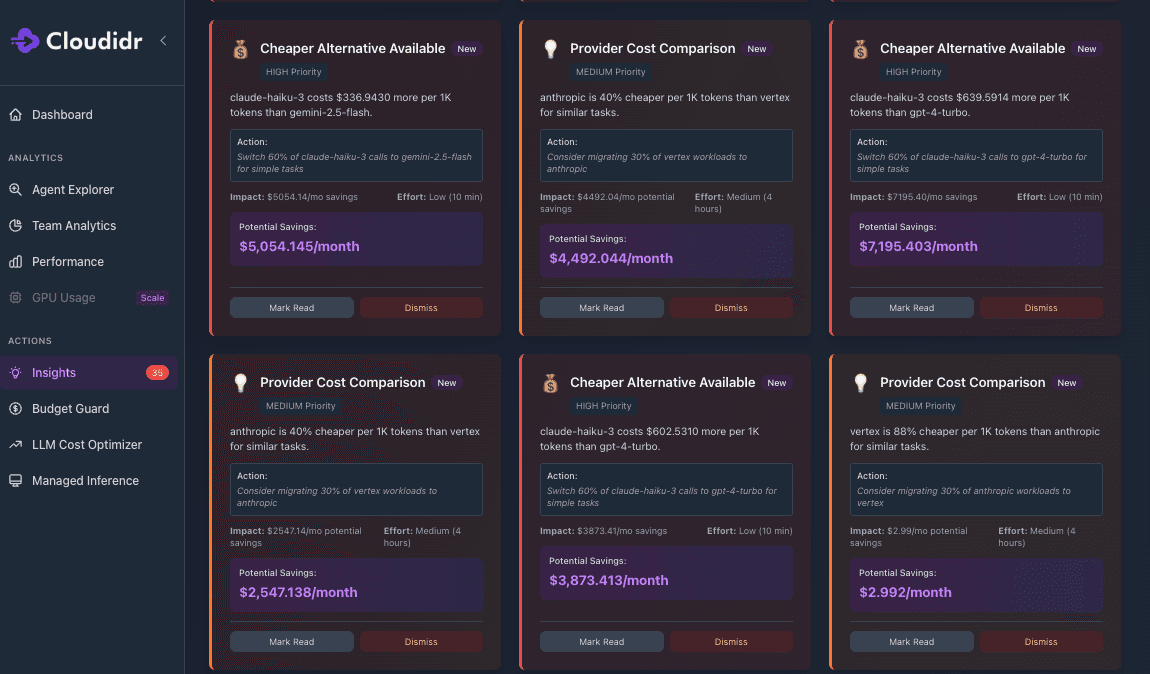
This is the capability that completes the AI FinOps loop. The platform doesn't wait for a human to spot that one model is responsible for nearly all costs. It tells you — with a prioritized action and a specific dollar figure. It doesn't require a FinOps engineer to compare provider pricing across workloads. It compares them automatically and surfaces the migration recommendation with an estimated ROI.
The insights engine continuously analyzes:
Model concentration risk (single model dominating costs)
Cross-provider price arbitrage opportunities
Workload-to-model fit (using expensive models for simple tasks)
Usage pattern anomalies suggesting runaway agents or loops
Budget trajectory forecasting (which agents are likely to breach limits)
Each insight is prioritized (High / Medium / Low), quantified in dollar impact, and paired with a specific, actionable recommendation and effort estimate. This is the difference between knowing you have a problem and knowing exactly what to do about it.
The 105-Model Problem: Why This Cannot Be Done Manually
Let's make the routing problem concrete with numbers from our own pricing tracker.
A development team in April 2026 has 105 models from the big three providers to evaluate — before considering the 2.7 million models available on Hugging Face or the models available through AWS Bedrock, Azure AI, and Google Vertex AI. Those 105 models span a 250x pricing spread: from Gemini 2.5 Flash-Lite at $0.10/$0.40 per million input/output tokens to GPT-5.4-Pro at $30/$180.
Choosing the wrong model tier — consistently routing to a model one level too expensive for the actual workload complexity — costs compounding money:
Monthly token volume | Wrong choice | Optimal choice | Monthly overspend |
|---|---|---|---|
500M tokens | Claude Sonnet 4.6 ($18/M) | Gemini 2.5 Flash ($2.80/M) | $7,600 |
1B tokens | GPT-4o ($12.50/M) | GPT-4o Mini ($0.75/M) | $11,750 |
2B tokens | GPT-5.2 ($15.75/M) | Gemini 2.5 Flash-Lite ($0.50/M) | $30,500 |
No engineering team has the bandwidth to continuously re-evaluate model selections as new models launch, prices change, and workload patterns shift. The model landscape changes faster than quarterly planning cycles. The LLM Cost Optimizer and Insights engine handle this continuously — adjusting routing, flagging concentration risks, and surfacing cross-provider arbitrage opportunities in real time.
Beyond APIs: Managed Inferencing and the Open-Source Advantage
The most sophisticated AI teams in 2026 are not choosing between commercial APIs and open-source models. They are using both — and the smartest ones are building a unified routing layer across the entire spectrum.
A new class of managed inference providers — Baseten, Fireworks.ai, and others — has emerged to serve teams that want the economics of open-source models without the overhead of managing GPU infrastructure. These providers offer API access to Llama, Mistral, Qwen, Deepseek, and other open-source models at a fraction of commercial API costs, with no servers to provision or maintain. For many workloads, they represent a compelling middle path between paying OpenAI prices and running your own GPU fleet.
Cloudidr's routing layer treats these providers as first-class citizens alongside OpenAI, Anthropic, and Google. Teams can capture open-source economics through a single integration point — with the same cost visibility, budget controls, routing intelligence, and Insights recommendations applied uniformly across the full provider stack. When the routing engine determines that a prompt doesn't require frontier model capability, it can route transparently to Cloudidr's own open source hosted models — without any changes to application code.
For teams that do want full control and data sovereignty — running models on their own GPU infrastructure for compliance or cost-at-scale reasons — Cloudidr's GPU Usage dashboard extend AI FinOps to the GPU infrastructure layer. This is the GPU equivalent of EC2 rightsizing.
The maximum flexibility in AI cost management comes from the ability to route dynamically across the full portfolio — frontier commercial APIs, managed open-source models, and self-hosted on-premise models — capturing the best economics for each workload, each compliance requirement, and each quality threshold, all through a single integration point with unified visibility across every provider.
Cloudidr Is Defining the AI FinOps Category
We built Cloudidr's LLM Ops platform because we believed — before it was obvious — that AI infrastructure costs would become one of the top line items on every technology company's P&L. That belief has been validated faster than we expected.
The category we're defining has three properties that make it structurally distinct from Cloud FinOps and impossible to replicate as a feature addition:
1. It requires semantic understanding of every request. Cloud FinOps operates at the resource level. AI FinOps operates at the content level. You cannot tag your way to a 90% cost reduction on LLM spend. You need a routing layer that understands what each prompt is asking and what tier of model it actually warrants.
2. It spans the full AI cost stack. LLM API costs, GPU compute, open-source inference, cross-provider routing — all under one roof, with unified visibility and optimization. No cloud monitoring tool covers this surface area, because the data models don't overlap.
3. It is action-oriented by design. Visibility without action is reporting. Insights without routing are suggestions. LLM Ops closes the loop — from surfacing an optimization opportunity in Insights to automatically applying it in the routing engine, with every request.
The companies that build AI FinOps discipline into their infrastructure now — while the model landscape is still early and pricing is still volatile — will have a structural cost advantage over those that treat AI spend as an unmanageable variable cost. The same was true of Cloud FinOps in 2014. It is true of AI FinOps in 2026.
Getting Started
You don't need to solve everything at once. The AI FinOps maturity arc maps directly to the four pillars:
Week 1: Connect your API keys. Get full visibility in minutes — spend by model, provider, team, project, and agent.
Week 2: Configure Budget Guard thresholds for your highest-cost agents. Prevent the next runway cost event.
Week 3: Enable the LLM Cost Optimizer. Let the routing engine start reducing costs automatically. Most teams see 40–60% blended savings within 30 days.
Ongoing: Review Insights weekly. Each recommendation is quantified with a dollar impact and an effort estimate. The platform finds the savings you didn't know to look for.
→ Start free — 2-line integration → Book a demo with Khursheed → Explore the 105-model pricing leaderboard → Learn more at llmfinops.ai
Key Takeaways
AI FinOps is not Cloud FinOps with an AI tab — it is a fundamentally different discipline requiring semantic routing, not inventory tagging. Cloud FinOps tools can show you the bill; they cannot reduce it.
The four pillars are: Visibility, Budget Guardrails, Intelligent Routing, and AI-Powered Insights — each building on the last, closing the full optimization loop.
105 models from three providers, 2.7M+ on Hugging Face — the model landscape is too complex and fast-moving for manual optimization at any meaningful scale.
Pricing variance between models is up to 250x — the difference between the right and wrong model choice is measured in hundreds of thousands of dollars annually.
Agentic workflows amplify every cost problem exponentially — Budget Guard and intelligent routing are not optional for teams running AI agents in production.
GPU costs are the invisible layer — teams self-hosting open-source models need the same cost visibility they have into API spend.
The best strategy is a hybrid one — routing intelligently across commercial APIs and self-hosted open-source models captures the best economics for every workload.
Optimization should be automatic — AI FinOps is not a quarterly review process. It is a real-time routing layer that optimizes every single request, and an Insights engine that continuously surfaces what the routing layer hasn't yet addressed.
Questions?
Have questions about LLM pricing or cost optimization?
Try LLM Ops free: llm-ops.cloudidr.com/signup
Book a demo: meetings.hubspot.com/khursheed-hassan
Email: hello@cloudidr.com
Connect on LinkedIn: Khursheed Hassan
We're always happy to help companies optimize their AI costs.