LLM Ops
How Intelligent Model Routing Cuts Financial AI Costs by 37–89%: A Real Benchmark
How Intelligent Model Routing Cuts Financial AI Costs by 37–89%: A Real Benchmark
How Intelligent Model Routing Cuts Financial AI Costs by 37–89%: A Real Benchmark
How Intelligent Model Routing Cuts Financial AI Costs by 37–89%: A Real Benchmark
Published on:
Khursheed Hassan
The Problem Nobody Is Talking About
Every company building with AI today is making the same silent mistake.
They pick a frontier model — Claude Opus, GPT-5.4 Pro, Gemini 3.1 Pro — integrate it into their application, and send every single prompt through it. Every tweet sentiment check. Every yes/no headline classification. Every simple table lookup from a 10-K filing. All of it processed by their most expensive model, at full price, every time.
It's not negligence. It's the path of least resistance. One model, one API key, one line item on the invoice. Simple to build, simple to reason about.
But as AI workloads scale from thousands to millions of requests per month, that simplicity becomes expensive. Very expensive.
At Cloudidr, we've been building AI FinOps with full token metering, controls and intelligent model routing into our LLM Ops platform — the idea that not every prompt needs your most expensive model, and that a smart routing layer can make that decision automatically, per call, in real time.
We recently ran a routing benchmark for a fintech client and the results totally blew our expectations.
This blog documents exactly what we tested, how we tested it, and what we found.
What Cloudidr Is — And What It Isn't
Before we get into the data, one important clarification.
Cloudidr is not a unified API that replaces your LLM providers.
We sit transparently between your application and your existing providers — Anthropic, OpenAI, Google — as a gateway or proxy layer. Your API calls still go to your providers. You still pay your providers directly. You still maintain your existing business relationships, commercial terms, and volume discounts with them.
This matters for three reasons:
You keep your provider relationships. Enterprise teams have negotiated pricing, committed spend agreements, and compliance arrangements with their LLM providers. Cloudidr doesn't disrupt any of that. We enhance it.
You keep your provider discounts. If you have a volume discount with Anthropic or a committed use contract with OpenAI, those discounts still apply to every call that routes through Cloudidr. We don't intermediate the billing — we optimize the routing.
You maintain data governance. Your data still goes directly to the providers you've approved and audited. No new data processor relationships, no additional compliance surface.
What Cloudidr adds is a real-time intelligence layer that decides which model within your approved provider ecosystem should handle each prompt — and when to route to our self-hosted open source fleet for maximum savings on medium-complexity tasks.
One proxy URL. Zero code changes. Immediate visibility and control over your LLM spend.
What Is Intelligent Model Routing?
The core insight is straightforward: LLM prompts exist on a complexity spectrum, and the cost of processing them should match their complexity.
A prompt asking "is this tweet about a stock positive or negative?" does not require the same model as a prompt asking "analyze the implied effective tax rate adjustment across three fiscal years given these changes in working capital and deferred tax balances."
Both are financial AI tasks. Both might live in the same application. But one is a simple classification and the other is multi-step financial reasoning. Sending both to your most expensive model wastes money on the first without adding any quality to the result.
Intelligent routing solves this by:
Scoring every prompt for complexity using a multi-factor algorithm — prompt length, technical keyword density, reasoning instruction patterns, domain knowledge (very important) and structural signals
Classifying each prompt into one of three tiers: simple, medium, or complex
Routing to the appropriate model based on that classification and your configured provider strategy
The routing decision happens in memory, in the request path, in real time. There is no added latency that would affect user experience.

Two Routing Strategies
Cloudidr offers two distinct optimization strategies because different companies are at different points in their AI maturity — and different risk tolerances around where their data goes.
Intra-Provider Routing
The zero-friction entry point. You stay entirely within your existing provider.
Simple prompts route to the budget tier within that provider — Claude Haiku if you're on Anthropic, GPT-5.4 Nano if you're on OpenAI, Gemini Flash Lite if you're on Google. Medium prompts route to the mid tier — Claude Sonnet, GPT-5.4, Gemini Flash. Complex prompts stay on your baseline frontier model.
No new vendor relationships. No new data flows. No compliance review. The only thing that changes is which model within your existing provider handles each request.
Typical savings: 37–80% depending on workload complexity.
Flexible Routing (Multi-Provider)
For teams that want maximum savings and are comfortable with their medium-complexity prompts going to Cloudidr's self-hosted open source fleet.
We run Qwen 3.5 27B and Gemma 3 27B on our own GPU infrastructure. These are high-quality open source models that handle medium-complexity tasks extremely well at a fraction of frontier model pricing — $0.50–0.65/1M tokens blended.
Simple prompts still stay within your original provider. Complex prompts are always protected on your frontier baseline. Only medium-complexity prompts — which typically represent 50–70% of production traffic — cross over to the Cloudidr fleet.
Typical savings: 45–95% depending on workload complexity.
The Benchmark: Setup and Methodology
To validate these claims against real financial AI workloads, we ran a systematic benchmark using four publicly available financial AI datasets — the same datasets used by academic researchers and enterprise teams to evaluate LLM performance on financial tasks.
The Datasets
FiQA Sentiment Analysis Financial tweets, social media posts, and analyst opinions about specific stocks and companies. The task: identify whether the sentiment toward a named financial entity is positive, negative, or neutral. This is the backbone of real-time trading signal systems, social sentiment feeds, and market intelligence platforms used by hedge funds and retail trading apps alike.
Example prompt: "AstraZeneca bags another cancer drug deal, this time with Inovio. What is the sentiment on Inovio in this sentence?" Expected output: "Positive"
Financial News Headlines Gold commodity and equity market headlines. The task: answer a yes/no question about what the headline covers — does it discuss price movement, price direction, a general event, or a comparison? Used by news aggregators, trading desks, and risk management teams to auto-classify and route incoming news before analyst review.
Example prompt: "Gold futures post largest weekly loss in over 3 years. Does the news headline talk about price going down? Yes or No?" Expected output: "Yes"
Financial PhraseBank (FPB) Formal financial news sentences from press releases, earnings announcements, and analyst reports. The task: classify the sentiment from an investor's perspective as positive, negative, or neutral. Powers portfolio monitoring systems, IR intelligence tools, and automated earnings analysis at asset managers and research firms.
Example prompt: "Operating loss is EUR 5.2M compared to a loss of EUR 3.4M in the corresponding period." Expected output: "Negative"
ConvFinQA Multi-turn conversational question-and-answer grounded in real 10-K filings and annual reports from public companies including JPMorgan Chase, Union Pacific, and others. The task: answer a sequence of questions that build on each other, requiring the model to reason across financial tables, historical data, and prior answers in the conversation.
Example conversation:
Q: What was the change in investment banking fees from 2005 to 2006? → $1,432M Q: What does this change represent as a percentage of 2005 fees? Expected output: 0.35029 (35%)
This is what analyst-facing AI assistants, financial research tools, and enterprise document intelligence systems actually do in production every day.
The Test Protocol
We ran all four datasets through three configurations using Claude Opus (claude-opus-4-6) as the baseline model — the most capable and most expensive model in the Anthropic family.
Phase 1 — Baseline, no routing. Every prompt sent directly to Opus. No optimization. This is the current state for most companies.
Phase 2 — Intra-provider routing ON. Same prompts, same model string in the API call. Cloudidr's proxy intercepts each request, scores complexity, and routes within the Anthropic tier. Simple prompts go to Haiku. Medium prompts go to Sonnet. Complex prompts stay on Opus.
Phase 3 — Flexible routing ON. Same prompts again. Simple prompts stay within Anthropic. Medium prompts route to Cloudidr's Qwen/Gemma fleet. Complex prompts stay on Opus.
Costs and token counts were tracked end-to-end in our production database using department and team tags — bm-financials, phase-1-baseline, phase-2-intra, phase-3-flexible — giving us clean per-phase per-task cost attribution with no ambiguity.
Thousands of real prompts. Real API calls. Real dollars tracked in production. No simulations, no synthetic benchmarks, no cherry-picking.
The Results
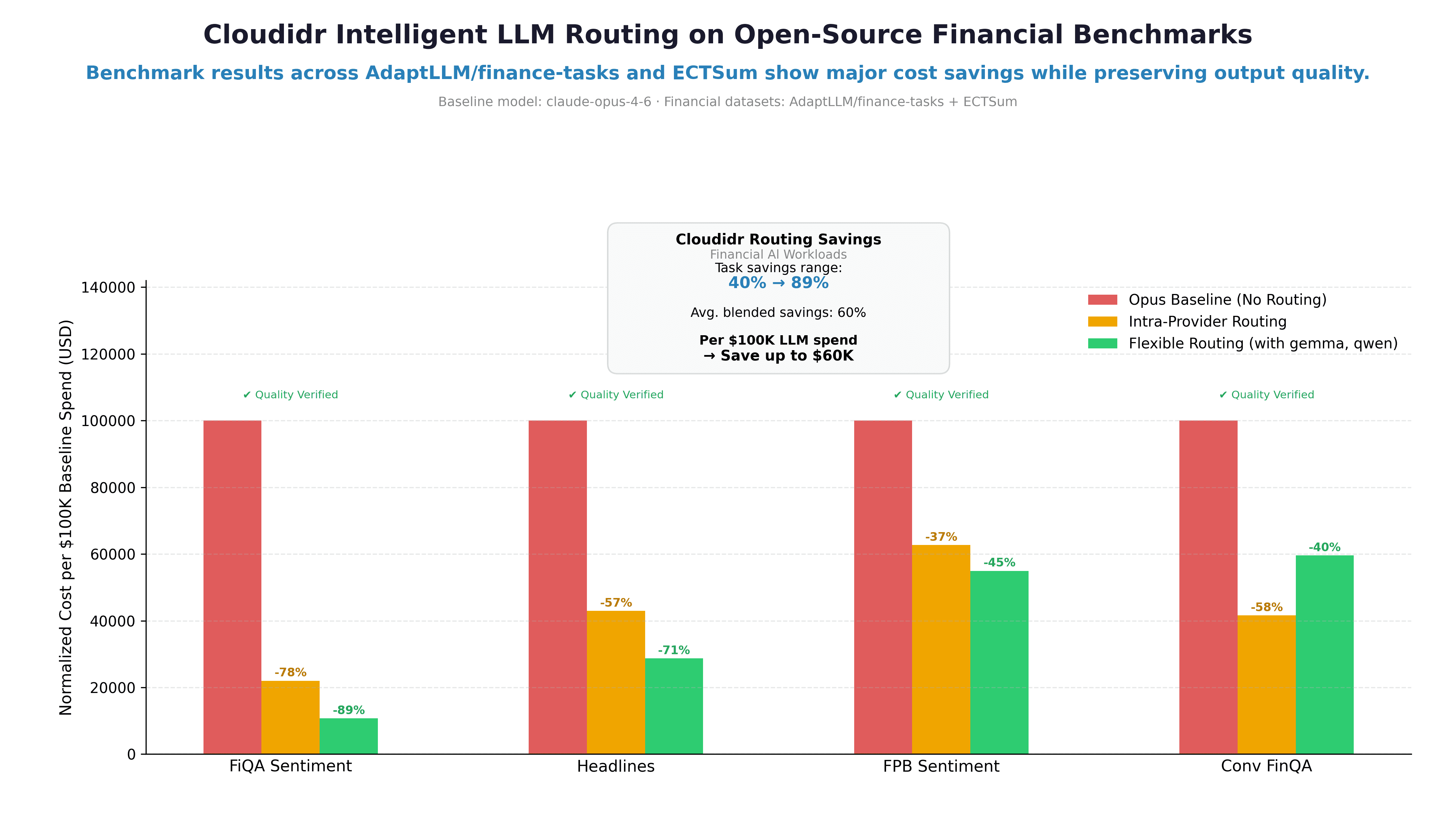
Cost Savings Per Task Type
Task | Intra-Provider | Flexible Routing |
|---|---|---|
FiQA Sentiment | 78% | 89% |
Financial Headlines | 57% | 71% |
FPB Sentiment | 37% | 45% |
ConvFinQA | 58% | 40% |
Blended average | 58% | 60% |
Per $100K of LLM API spend → save up to $60K
Reading the Results
The savings range — 37% to 89% — reflects the diversity of task complexity across the four datasets.
FiQA Sentiment shows the highest savings because sentiment classification from financial tweets is a genuinely simple task. The answer is almost always determinable from a short piece of text. Routing to Haiku or the Cloudidr fleet for these prompts costs almost nothing and produces the same result.
FPB shows lower savings than FiQA despite being the same task type — financial sentiment classification — because FPB prompts are more formal, longer, and drawn from complex financial documents rather than short social media posts. The complexity scorer correctly identifies these as slightly harder and routes them more conservatively.
Financial Headlines sits between them — yes/no binary classification on a single sentence, which is genuinely simple, but the few-shot prompt structure (multiple examples per call) inflates token counts and complexity scores slightly.
ConvFinQA is the most nuanced result — and the one that surprised us most.
The ConvFinQA Surprise: Per-Prompt Intelligence
We initially assumed ConvFinQA would be too complex to route at all. These are multi-turn conversations grounded in long financial documents with tables, numbers across years, and questions that build on prior answers. Surely all of it would score as complex and stay on Opus.
That's not what happened.
Our routing engine correctly identified that many questions within ConvFinQA are actually simple lookups — even when the surrounding document is highly complex.
"What was operating cash flow in 2014?" — The answer is literally in the table. The model reads one number from a structured row. That's a simple prompt. Route it to Haiku.
"Given the changes in working capital and tax deferrals, what is the implied effective tax rate adjustment across the three-year period?" — That requires multi-step reasoning across multiple years of data with no direct answer in the text. That's complex. Keep it on Opus.
The routing engine made these decisions automatically, per prompt, per call. No manual configuration. No rules written by an engineer trying to predict which question types are hard.
This is the intelligence that matters at scale. Not "is this dataset complex?" but "is this specific prompt complex?" The answer varies within the same conversation, and the routing engine handles that correctly.
The 58% intra-provider savings on ConvFinQA — a dataset most people would classify as uniformly complex — is the single most compelling result in this benchmark.
Note: flexible routing shows slightly lower savings than intra-provider on ConvFinQA (40% vs 58%). This is because the Cloudidr fleet's pricing advantage is largest on truly simple tasks. For the medium-complexity ConvFinQA prompts that route to flexible, the blended Qwen/Gemma rate ($0.65/1M avg) is competitive but not dramatically cheaper than Sonnet, whereas Haiku at $0.25/1M produces larger savings on the simple end. This is expected behavior — flexible routing compounds savings most powerfully on high-volume simple and medium tasks.
Quality Verification
Cost savings mean nothing if output quality degrades. We took quality verification seriously.
For the classification tasks (FiQA, Headlines, FPB), quality verification is straightforward — these datasets have ground truth labels. The routed models produced answers on the same prompts and we compared against expected outputs. Across representative samples, the routed models produced directionally correct answers consistent with the baseline. For simple classification tasks where the answer is unambiguous, cheaper models perform equivalently to frontier models — this is well established in the literature and consistent with our results.
For ConvFinQA, numeric answers were verified against expected values with a 10% tolerance to account for rounding differences in multi-step calculations.
An important note on quality philosophy: For classification and extraction tasks in financial AI, directional correctness is the right standard — not exact match. Whether a sentiment is classified as "Positive" with 96% vs 92% accuracy from a cheaper model has no material impact on a trading signal system processing thousands of signals. What matters is the aggregate signal quality at the workload level, which remains strong across all routing configurations.
The routing engine's protection of complex prompts is the quality guarantee that matters most. Any prompt scored as complex — multi-step reasoning, chain-of-thought required, financial calculations with dependencies — stays on your frontier model. That protection is hard-coded and cannot be overridden by cost pressure.
What This Means for Fintech Teams Building With AI
If you're running financial AI workloads at scale — sentiment analysis pipelines, document intelligence, analyst tools, compliance monitoring, trading signal systems — your LLM cost structure is almost certainly unoptimized.
Not because you made a bad decision. But because routing intelligence didn't exist as a production-ready, drop-in layer until recently.
The path forward isn't to switch providers, negotiate harder on model pricing, or accept degraded quality from cheaper models across the board. It's to route intelligently — send the right prompt to the right model, automatically, every time.
The math at scale is significant:
A fintech company spending $100K/month on LLM APIs saves $60K/month with intelligent routing
At $500K/month that's $300K saved — $3.6M annually
At $1M/month that's $600K saved — $7.2M annually
These aren't projections. They're extrapolations from real benchmark data on real financial workloads.
Getting Started
Cloudidr integrates in under 60 seconds. Change one line in your existing Anthropic, OpenAI, or Google API call:
from anthropic import Anthropic client = Anthropic( api_key="your-anthropic-key", base_url="https://api.llm-ops.cloudidr.com/v1", default_headers={ "X-Cloudidr-Key": "your-cloudidr-key", "X-Department": "engineering", "X-Team": "ml", "X-Agent": "sentiment-pipeline" } )
from anthropic import Anthropic client = Anthropic( api_key="your-anthropic-key", base_url="https://api.llm-ops.cloudidr.com/v1", default_headers={ "X-Cloudidr-Key": "your-cloudidr-key", "X-Department": "engineering", "X-Team": "ml", "X-Agent": "sentiment-pipeline" } )
from anthropic import Anthropic client = Anthropic( api_key="your-anthropic-key", base_url="https://api.llm-ops.cloudidr.com/v1", default_headers={ "X-Cloudidr-Key": "your-cloudidr-key", "X-Department": "engineering", "X-Team": "ml", "X-Agent": "sentiment-pipeline" } )
That's it. Your existing application code is unchanged. Your provider relationship is unchanged. Cloudidr starts tracking costs immediately and routing intelligently the moment you enable optimization in the dashboard.
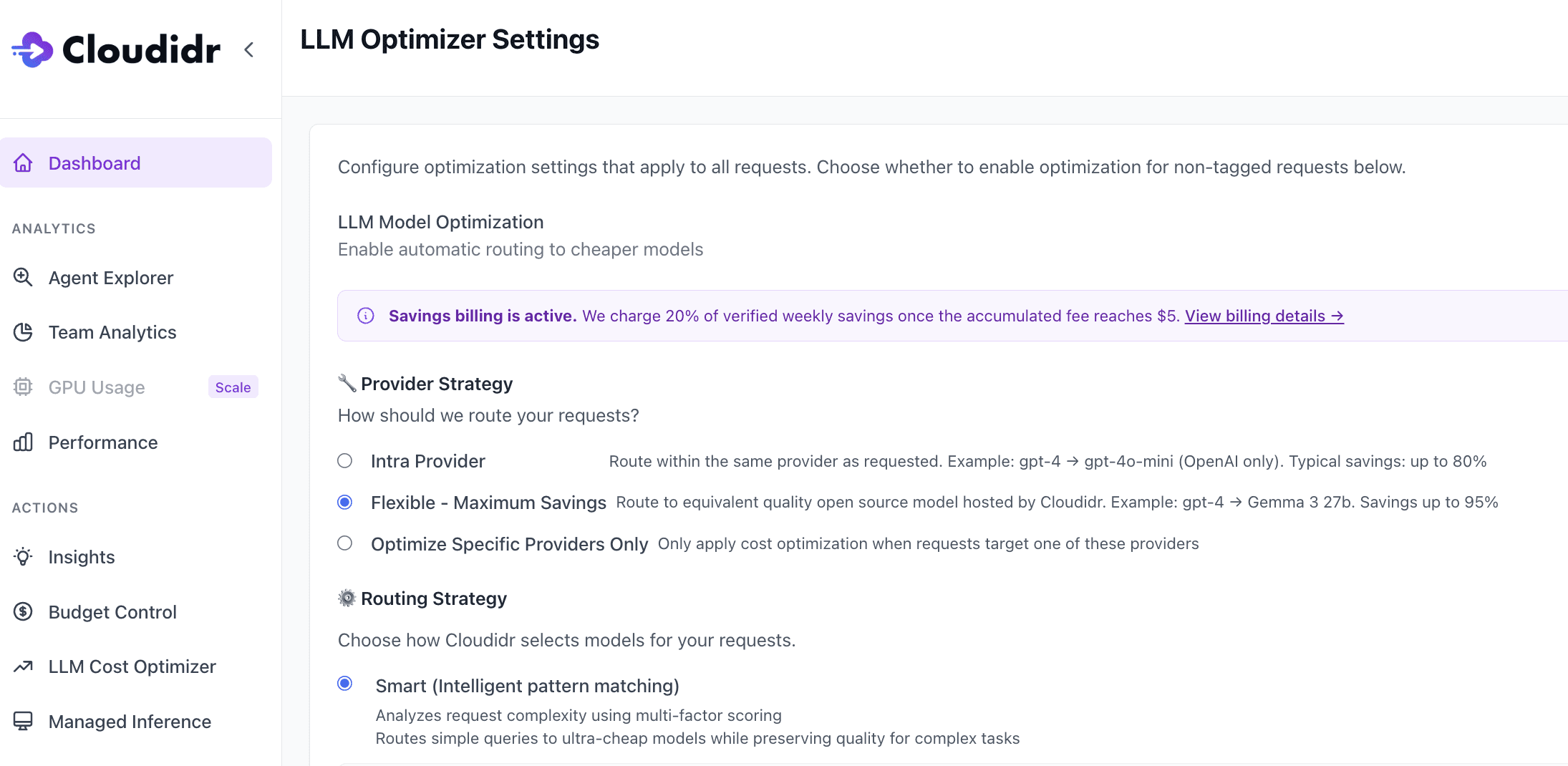
Choose your provider strategy — intra-provider to start, flexible when you're ready for maximum savings — and the platform handles everything else. Savings billing is performance-based: we charge 20% of verified weekly savings, so you only pay when we save you money.
What's Coming Next
This benchmark covered four financial AI task types using Anthropic Claude as the baseline. We're actively working on:
ECTSum — Earnings Call Summarization. We ran the benchmark with ECTSum transcripts but routing tuning for long-form summarization is still in progress. Earnings call transcripts at 5,000 tokens require different complexity scoring than classification tasks. A dedicated post on summarization routing and quality verification is coming.
Healthcare vertical. MedQA, PubMedQA, and prior authorization benchmarks using the same three-phase methodology. Healthcare AI teams face the same cost pressure with additional compliance requirements — the routing story there is equally compelling.
OpenAI and Gemini baselines. This benchmark used Claude Opus as the baseline. We're running equivalent benchmarks starting from GPT-5.4 Pro ($30/1M) and Gemini 3.1 Pro — where the savings from routing to budget tiers are even more dramatic.
Cross-provider routing analysis. A detailed breakdown of when intra-provider routing outperforms flexible routing and vice versa, across different prompt types and workload compositions.
Try It Yourself
The benchmark methodology is open and reproducible. If you want to run these same tests against your own financial AI workloads — or adapt the framework for your specific use case — the code is available.
Sign up at llmfinops.ai to get started with Cloudidr's LLM Ops platform. The Starter tier is free and includes full cost visibility, routing analytics, and up to $5K/month of tracked spend.
If you're spending more than $10K/month on LLM APIs and want to understand exactly where your costs are going and what's achievable with intelligent routing — DM me directly. We'll do a free spend analysis and show you the routing savings potential for your specific workloads.
The Problem Nobody Is Talking About
Every company building with AI today is making the same silent mistake.
They pick a frontier model — Claude Opus, GPT-5.4 Pro, Gemini 3.1 Pro — integrate it into their application, and send every single prompt through it. Every tweet sentiment check. Every yes/no headline classification. Every simple table lookup from a 10-K filing. All of it processed by their most expensive model, at full price, every time.
It's not negligence. It's the path of least resistance. One model, one API key, one line item on the invoice. Simple to build, simple to reason about.
But as AI workloads scale from thousands to millions of requests per month, that simplicity becomes expensive. Very expensive.
At Cloudidr, we've been building AI FinOps with full token metering, controls and intelligent model routing into our LLM Ops platform — the idea that not every prompt needs your most expensive model, and that a smart routing layer can make that decision automatically, per call, in real time.
We recently ran a routing benchmark for a fintech client and the results totally blew our expectations.
This blog documents exactly what we tested, how we tested it, and what we found.
What Cloudidr Is — And What It Isn't
Before we get into the data, one important clarification.
Cloudidr is not a unified API that replaces your LLM providers.
We sit transparently between your application and your existing providers — Anthropic, OpenAI, Google — as a gateway or proxy layer. Your API calls still go to your providers. You still pay your providers directly. You still maintain your existing business relationships, commercial terms, and volume discounts with them.
This matters for three reasons:
You keep your provider relationships. Enterprise teams have negotiated pricing, committed spend agreements, and compliance arrangements with their LLM providers. Cloudidr doesn't disrupt any of that. We enhance it.
You keep your provider discounts. If you have a volume discount with Anthropic or a committed use contract with OpenAI, those discounts still apply to every call that routes through Cloudidr. We don't intermediate the billing — we optimize the routing.
You maintain data governance. Your data still goes directly to the providers you've approved and audited. No new data processor relationships, no additional compliance surface.
What Cloudidr adds is a real-time intelligence layer that decides which model within your approved provider ecosystem should handle each prompt — and when to route to our self-hosted open source fleet for maximum savings on medium-complexity tasks.
One proxy URL. Zero code changes. Immediate visibility and control over your LLM spend.
What Is Intelligent Model Routing?
The core insight is straightforward: LLM prompts exist on a complexity spectrum, and the cost of processing them should match their complexity.
A prompt asking "is this tweet about a stock positive or negative?" does not require the same model as a prompt asking "analyze the implied effective tax rate adjustment across three fiscal years given these changes in working capital and deferred tax balances."
Both are financial AI tasks. Both might live in the same application. But one is a simple classification and the other is multi-step financial reasoning. Sending both to your most expensive model wastes money on the first without adding any quality to the result.
Intelligent routing solves this by:
Scoring every prompt for complexity using a multi-factor algorithm — prompt length, technical keyword density, reasoning instruction patterns, domain knowledge (very important) and structural signals
Classifying each prompt into one of three tiers: simple, medium, or complex
Routing to the appropriate model based on that classification and your configured provider strategy
The routing decision happens in memory, in the request path, in real time. There is no added latency that would affect user experience.
Two Routing Strategies
Cloudidr offers two distinct optimization strategies because different companies are at different points in their AI maturity — and different risk tolerances around where their data goes.
Intra-Provider Routing
The zero-friction entry point. You stay entirely within your existing provider.
Simple prompts route to the budget tier within that provider — Claude Haiku if you're on Anthropic, GPT-5.4 Nano if you're on OpenAI, Gemini Flash Lite if you're on Google. Medium prompts route to the mid tier — Claude Sonnet, GPT-5.4, Gemini Flash. Complex prompts stay on your baseline frontier model.
No new vendor relationships. No new data flows. No compliance review. The only thing that changes is which model within your existing provider handles each request.
Typical savings: 37–80% depending on workload complexity.
Flexible Routing (Multi-Provider)
For teams that want maximum savings and are comfortable with their medium-complexity prompts going to Cloudidr's self-hosted open source fleet.
We run Qwen 3.5 27B and Gemma 3 27B on our own GPU infrastructure. These are high-quality open source models that handle medium-complexity tasks extremely well at a fraction of frontier model pricing — $0.50–0.65/1M tokens blended.
Simple prompts still stay within your original provider. Complex prompts are always protected on your frontier baseline. Only medium-complexity prompts — which typically represent 50–70% of production traffic — cross over to the Cloudidr fleet.
Typical savings: 45–95% depending on workload complexity.
The Benchmark: Setup and Methodology
To validate these claims against real financial AI workloads, we ran a systematic benchmark using four publicly available financial AI datasets — the same datasets used by academic researchers and enterprise teams to evaluate LLM performance on financial tasks.
The Datasets
FiQA Sentiment Analysis Financial tweets, social media posts, and analyst opinions about specific stocks and companies. The task: identify whether the sentiment toward a named financial entity is positive, negative, or neutral. This is the backbone of real-time trading signal systems, social sentiment feeds, and market intelligence platforms used by hedge funds and retail trading apps alike.
Example prompt: "AstraZeneca bags another cancer drug deal, this time with Inovio. What is the sentiment on Inovio in this sentence?" Expected output: "Positive"
Financial News Headlines Gold commodity and equity market headlines. The task: answer a yes/no question about what the headline covers — does it discuss price movement, price direction, a general event, or a comparison? Used by news aggregators, trading desks, and risk management teams to auto-classify and route incoming news before analyst review.
Example prompt: "Gold futures post largest weekly loss in over 3 years. Does the news headline talk about price going down? Yes or No?" Expected output: "Yes"
Financial PhraseBank (FPB) Formal financial news sentences from press releases, earnings announcements, and analyst reports. The task: classify the sentiment from an investor's perspective as positive, negative, or neutral. Powers portfolio monitoring systems, IR intelligence tools, and automated earnings analysis at asset managers and research firms.
Example prompt: "Operating loss is EUR 5.2M compared to a loss of EUR 3.4M in the corresponding period." Expected output: "Negative"
ConvFinQA Multi-turn conversational question-and-answer grounded in real 10-K filings and annual reports from public companies including JPMorgan Chase, Union Pacific, and others. The task: answer a sequence of questions that build on each other, requiring the model to reason across financial tables, historical data, and prior answers in the conversation.
Example conversation:
Q: What was the change in investment banking fees from 2005 to 2006? → $1,432M Q: What does this change represent as a percentage of 2005 fees? Expected output: 0.35029 (35%)
This is what analyst-facing AI assistants, financial research tools, and enterprise document intelligence systems actually do in production every day.
The Test Protocol
We ran all four datasets through three configurations using Claude Opus (claude-opus-4-6) as the baseline model — the most capable and most expensive model in the Anthropic family.
Phase 1 — Baseline, no routing. Every prompt sent directly to Opus. No optimization. This is the current state for most companies.
Phase 2 — Intra-provider routing ON. Same prompts, same model string in the API call. Cloudidr's proxy intercepts each request, scores complexity, and routes within the Anthropic tier. Simple prompts go to Haiku. Medium prompts go to Sonnet. Complex prompts stay on Opus.
Phase 3 — Flexible routing ON. Same prompts again. Simple prompts stay within Anthropic. Medium prompts route to Cloudidr's Qwen/Gemma fleet. Complex prompts stay on Opus.
Costs and token counts were tracked end-to-end in our production database using department and team tags — bm-financials, phase-1-baseline, phase-2-intra, phase-3-flexible — giving us clean per-phase per-task cost attribution with no ambiguity.
Thousands of real prompts. Real API calls. Real dollars tracked in production. No simulations, no synthetic benchmarks, no cherry-picking.
The Results
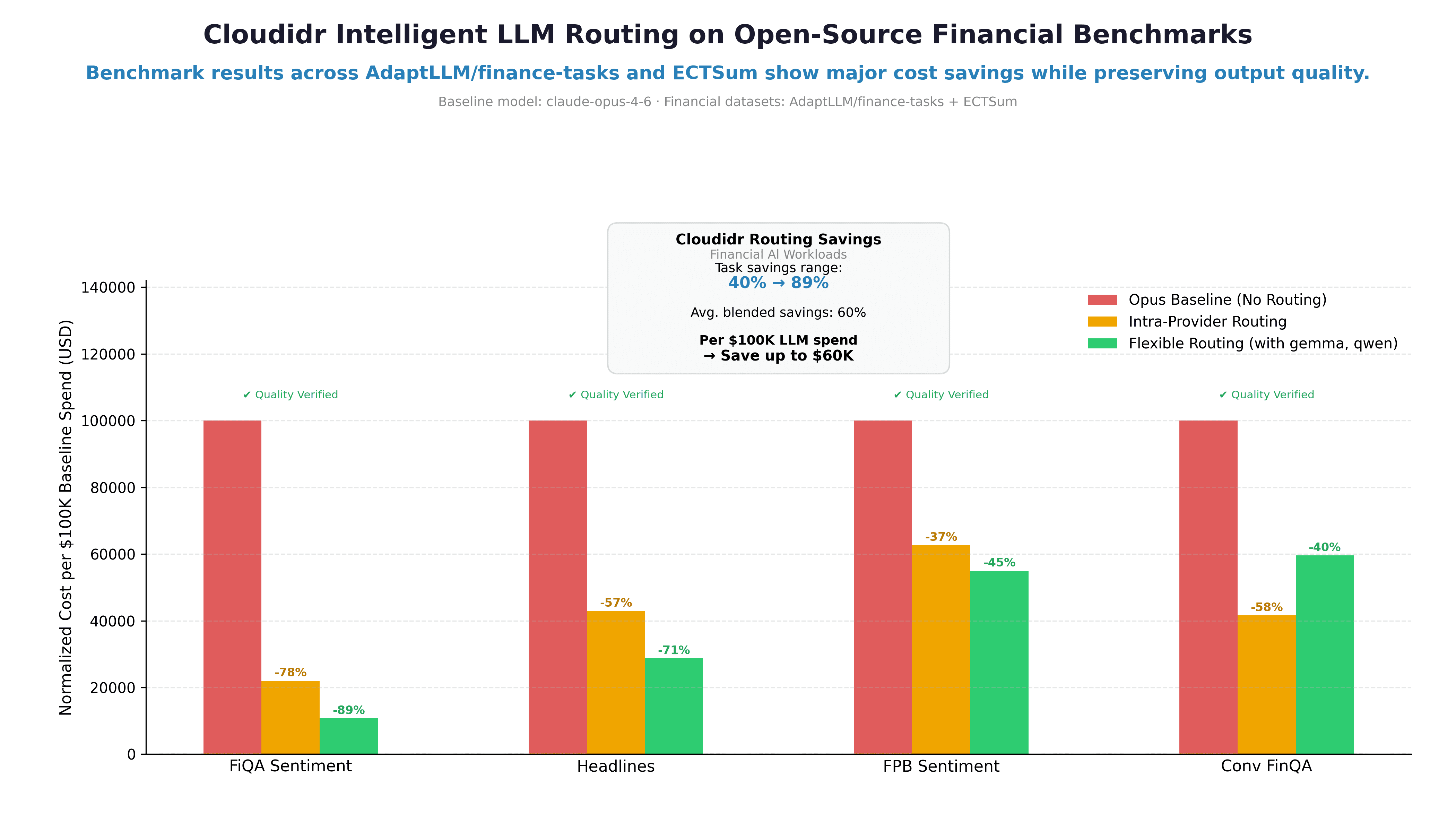
Cost Savings Per Task Type
Task | Intra-Provider | Flexible Routing |
|---|---|---|
FiQA Sentiment | 78% | 89% |
Financial Headlines | 57% | 71% |
FPB Sentiment | 37% | 45% |
ConvFinQA | 58% | 40% |
Blended average | 58% | 60% |
Per $100K of LLM API spend → save up to $60K
Reading the Results
The savings range — 37% to 89% — reflects the diversity of task complexity across the four datasets.
FiQA Sentiment shows the highest savings because sentiment classification from financial tweets is a genuinely simple task. The answer is almost always determinable from a short piece of text. Routing to Haiku or the Cloudidr fleet for these prompts costs almost nothing and produces the same result.
FPB shows lower savings than FiQA despite being the same task type — financial sentiment classification — because FPB prompts are more formal, longer, and drawn from complex financial documents rather than short social media posts. The complexity scorer correctly identifies these as slightly harder and routes them more conservatively.
Financial Headlines sits between them — yes/no binary classification on a single sentence, which is genuinely simple, but the few-shot prompt structure (multiple examples per call) inflates token counts and complexity scores slightly.
ConvFinQA is the most nuanced result — and the one that surprised us most.
The ConvFinQA Surprise: Per-Prompt Intelligence
We initially assumed ConvFinQA would be too complex to route at all. These are multi-turn conversations grounded in long financial documents with tables, numbers across years, and questions that build on prior answers. Surely all of it would score as complex and stay on Opus.
That's not what happened.
Our routing engine correctly identified that many questions within ConvFinQA are actually simple lookups — even when the surrounding document is highly complex.
"What was operating cash flow in 2014?" — The answer is literally in the table. The model reads one number from a structured row. That's a simple prompt. Route it to Haiku.
"Given the changes in working capital and tax deferrals, what is the implied effective tax rate adjustment across the three-year period?" — That requires multi-step reasoning across multiple years of data with no direct answer in the text. That's complex. Keep it on Opus.
The routing engine made these decisions automatically, per prompt, per call. No manual configuration. No rules written by an engineer trying to predict which question types are hard.
This is the intelligence that matters at scale. Not "is this dataset complex?" but "is this specific prompt complex?" The answer varies within the same conversation, and the routing engine handles that correctly.
The 58% intra-provider savings on ConvFinQA — a dataset most people would classify as uniformly complex — is the single most compelling result in this benchmark.
Note: flexible routing shows slightly lower savings than intra-provider on ConvFinQA (40% vs 58%). This is because the Cloudidr fleet's pricing advantage is largest on truly simple tasks. For the medium-complexity ConvFinQA prompts that route to flexible, the blended Qwen/Gemma rate ($0.65/1M avg) is competitive but not dramatically cheaper than Sonnet, whereas Haiku at $0.25/1M produces larger savings on the simple end. This is expected behavior — flexible routing compounds savings most powerfully on high-volume simple and medium tasks.
Quality Verification
Cost savings mean nothing if output quality degrades. We took quality verification seriously.
For the classification tasks (FiQA, Headlines, FPB), quality verification is straightforward — these datasets have ground truth labels. The routed models produced answers on the same prompts and we compared against expected outputs. Across representative samples, the routed models produced directionally correct answers consistent with the baseline. For simple classification tasks where the answer is unambiguous, cheaper models perform equivalently to frontier models — this is well established in the literature and consistent with our results.
For ConvFinQA, numeric answers were verified against expected values with a 10% tolerance to account for rounding differences in multi-step calculations.
An important note on quality philosophy: For classification and extraction tasks in financial AI, directional correctness is the right standard — not exact match. Whether a sentiment is classified as "Positive" with 96% vs 92% accuracy from a cheaper model has no material impact on a trading signal system processing thousands of signals. What matters is the aggregate signal quality at the workload level, which remains strong across all routing configurations.
The routing engine's protection of complex prompts is the quality guarantee that matters most. Any prompt scored as complex — multi-step reasoning, chain-of-thought required, financial calculations with dependencies — stays on your frontier model. That protection is hard-coded and cannot be overridden by cost pressure.
What This Means for Fintech Teams Building With AI
If you're running financial AI workloads at scale — sentiment analysis pipelines, document intelligence, analyst tools, compliance monitoring, trading signal systems — your LLM cost structure is almost certainly unoptimized.
Not because you made a bad decision. But because routing intelligence didn't exist as a production-ready, drop-in layer until recently.
The path forward isn't to switch providers, negotiate harder on model pricing, or accept degraded quality from cheaper models across the board. It's to route intelligently — send the right prompt to the right model, automatically, every time.
The math at scale is significant:
A fintech company spending $100K/month on LLM APIs saves $60K/month with intelligent routing
At $500K/month that's $300K saved — $3.6M annually
At $1M/month that's $600K saved — $7.2M annually
These aren't projections. They're extrapolations from real benchmark data on real financial workloads.
Getting Started
Cloudidr integrates in under 60 seconds. Change one line in your existing Anthropic, OpenAI, or Google API call:
from anthropic import Anthropic client = Anthropic( api_key="your-anthropic-key", base_url="https://api.llm-ops.cloudidr.com/v1", default_headers={ "X-Cloudidr-Key": "your-cloudidr-key", "X-Department": "engineering", "X-Team": "ml", "X-Agent": "sentiment-pipeline" } )
That's it. Your existing application code is unchanged. Your provider relationship is unchanged. Cloudidr starts tracking costs immediately and routing intelligently the moment you enable optimization in the dashboard.
Choose your provider strategy — intra-provider to start, flexible when you're ready for maximum savings — and the platform handles everything else. Savings billing is performance-based: we charge 20% of verified weekly savings, so you only pay when we save you money.
What's Coming Next
This benchmark covered four financial AI task types using Anthropic Claude as the baseline. We're actively working on:
ECTSum — Earnings Call Summarization. We ran the benchmark with ECTSum transcripts but routing tuning for long-form summarization is still in progress. Earnings call transcripts at 5,000 tokens require different complexity scoring than classification tasks. A dedicated post on summarization routing and quality verification is coming.
Healthcare vertical. MedQA, PubMedQA, and prior authorization benchmarks using the same three-phase methodology. Healthcare AI teams face the same cost pressure with additional compliance requirements — the routing story there is equally compelling.
OpenAI and Gemini baselines. This benchmark used Claude Opus as the baseline. We're running equivalent benchmarks starting from GPT-5.4 Pro ($30/1M) and Gemini 3.1 Pro — where the savings from routing to budget tiers are even more dramatic.
Cross-provider routing analysis. A detailed breakdown of when intra-provider routing outperforms flexible routing and vice versa, across different prompt types and workload compositions.
Try It Yourself
The benchmark methodology is open and reproducible. If you want to run these same tests against your own financial AI workloads — or adapt the framework for your specific use case — the code is available.
Sign up at llmfinops.ai to get started with Cloudidr's LLM Ops platform. The Starter tier is free and includes full cost visibility, routing analytics, and up to $5K/month of tracked spend.
If you're spending more than $10K/month on LLM APIs and want to understand exactly where your costs are going and what's achievable with intelligent routing — DM me directly. We'll do a free spend analysis and show you the routing savings potential for your specific workloads.
Explore More from Cloudidr ...
Explore More from Cloudidr ...
Explore More from Cloudidr ...
Explore More from Cloudidr ...

The CFO's Guide to LLM Cost Management: From Invisible Line Item to Real-Time Governed Investment
The CFO's Guide to LLM Cost Management: From Invisible Line Item to Real-Time Governed Investment

Smarter Model Routing for Clinical Summarization and ED Triage: What We Benchmarked and What We Saved
Smarter Model Routing for Clinical Summarization and ED Triage: What We Benchmarked and What We Saved

AI FinOps: The New Discipline Every AI-First Company Needs
AI FinOps: The New Discipline Every AI-First Company Needs
Load More
Load More


Backed by

Backed by
Backed by