LLM Ops
Smarter Model Routing for Clinical Summarization and ED Triage: What We Benchmarked and What We Saved
Smarter Model Routing for Clinical Summarization and ED Triage: What We Benchmarked and What We Saved
Smarter Model Routing for Clinical Summarization and ED Triage: What We Benchmarked and What We Saved
Smarter Model Routing for Clinical Summarization and ED Triage: What We Benchmarked and What We Saved
Published on:
Khursheed Hassan , Founder & CEO Cloudidr

TL;DR
In our benchmark run, we measured 77–99% cost savings across clinical summarization and ED triage tasks using intelligent model routing — with quality checks passing on every task. Teams without a routing layer are likely leaving similar savings on the table, but your numbers will depend on your provider, model mix, and traffic distribution.
We benchmarked Cloudidr's intelligent model routing on four public clinical datasets: two summarization tasks (Asclepius synthetic clinical notes and MTSamples transcriptions) and two emergency triage tasks (Syntech and Africa ED). The baseline was gemini-3.1-pro-preview with no routing. The routed phase used intra-provider routing — staying within the same provider family.
Results: 77–99% cost savings across all four tasks. Costs are measured from tagged benchmark traffic; quality is evaluated on the same runs as a parallel track via ROUGE, LLM-as-judge scoring, and triage accuracy. Per $100K of LLM spend, our run showed savings up to $83K. Quality checks passed on every task.
The rest of this post covers exactly how we measured that — datasets, data examples, quality methodology, and results in full. All four datasets used are public on Hugging Face — links at the bottom of this post.
The Healthcare LLM Dilemma
Healthcare teams are under more pressure than ever to deploy LLMs for clinical documentation, summarization, and triage support — but two concerns slow every conversation: quality and cost.
Quality because the stakes are high. A hallucinated lab value, a missed urgency flag, a compressed note that drops a critical intervention — these are not software bugs, they are patient safety concerns. Quality evaluation in healthcare AI cannot be "does the output look reasonable." It needs to be grounded in clinical reference standards.
Cost because API spend on frontier models scales fast. A hospital system running clinical summarization across thousands of discharge notes per day on a premium model is spending significantly more than it needs to — and most teams have no visibility into whether a cheaper model could do the same job at the same quality level.
Cloudidr's intelligent model routing addresses both. This post benchmarks routing across four public clinical datasets — two summarization tasks and two emergency triage tasks — and reports cost savings alongside clinically grounded quality evaluation. The goal is a transparent, reproducible story: open datasets, documented methodology, and a quality gate that ensures savings are not "cheap at the price of safety."
The Four Datasets — What We Used and Why
We chose two summarization datasets and two triage datasets deliberately. Together they cover the two most common high-value LLM use cases in clinical settings, and they stress-test different model behaviors.
Summarization Pair
Asclepius — Synthetic Clinical Notes (starmpcc/Asclepius-Synthetic-Clinical-Notes)
Structured hospital course notes with a reference answer. Ideal for testing coherence and clinical detail on long-form notes — ICU admissions, surgical courses, and complex medical hospitalizations.
MTSamples — Medical Transcriptions (harishnair04/mtsamples)
Realistic clinical dictation transcriptions across multiple specialties — allergy, orthopedics, cardiology, and more. The transcription field (often long dictation-style notes spanning multiple sections) is the input; the description field provides a short reference summary the model output is scored against. This creates a demanding compression task: the model must distill rich clinical detail down to the essential presenting problem without losing relevant information.
The two datasets complement each other deliberately. Asclepius evaluates whether a model can answer a specific clinical question about a hospital course with accuracy. MTSamples evaluates whether a model can compress a dense transcription into a concise summary — a different skill, and a harder one to fake.
Triage Pair
Syntech Medical Triage 500 (syntech-ai/medical-triage-500)
Structured clinical vignettes with patient demographics, symptom presentation, duration, onset, context, and red flags. Each case carries a reference label (urgency_category): Immediate, Urgent, Semi-urgent, or Non-urgent. Note that Syntech is a fully synthetic dataset created for AI prototyping and triage classification research — not clinical records. The model receives a short vignette prompt and must answer with one of those four labels — no reasoning, no hedging. Accuracy is measured against the dataset's reference label.
Africa Emergency Triage System (electricsheepafrica/emergency-triage-systems)
Emergency triage scenarios from African healthcare contexts, covering a different patient population, clinical vocabulary, and triage schema. Each row carries a true_acuity label used as the gold standard. This dataset complements Syntech by testing whether routing quality holds across different geographies and clinical settings — not just Western hospital presentations.
The two triage datasets together test whether a routed model maintains classification accuracy on high-stakes, short-output tasks across diverse populations. A wrong urgency call — Non-urgent when the case is Immediate — is a meaningful error, and the quality gate reflects that.
The Data in Practice — What the Models Are Actually Evaluating
Asclepius: Hospital Course Summarization
Here is a representative Asclepius row — the shape of data the models process in the summarization benchmark:
Input note (abbreviated):
Hospital Course Summary: Patient: Male, Age 57 Admission Diagnosis: Oxygen Desaturation The patient was admitted to the ICU one week after a positive COVID-19 result due to oxygen desaturation. Physical therapy was initiated promptly after admission, which helped improve the patient's breathing frequency and oxygen saturation. The patient was guided to achieve a prone position resulting in a significant increase in oxygen saturation from 88% to 96%... After three days with this regime, the patient was transferred to the normal ward. After nine days from ICU admission, the patient was successfully discharged from the hospital as a pedestrian
Hospital Course Summary: Patient: Male, Age 57 Admission Diagnosis: Oxygen Desaturation The patient was admitted to the ICU one week after a positive COVID-19 result due to oxygen desaturation. Physical therapy was initiated promptly after admission, which helped improve the patient's breathing frequency and oxygen saturation. The patient was guided to achieve a prone position resulting in a significant increase in oxygen saturation from 88% to 96%... After three days with this regime, the patient was transferred to the normal ward. After nine days from ICU admission, the patient was successfully discharged from the hospital as a pedestrian
Hospital Course Summary: Patient: Male, Age 57 Admission Diagnosis: Oxygen Desaturation The patient was admitted to the ICU one week after a positive COVID-19 result due to oxygen desaturation. Physical therapy was initiated promptly after admission, which helped improve the patient's breathing frequency and oxygen saturation. The patient was guided to achieve a prone position resulting in a significant increase in oxygen saturation from 88% to 96%... After three days with this regime, the patient was transferred to the normal ward. After nine days from ICU admission, the patient was successfully discharged from the hospital as a pedestrian
Question: What were the key improvements in the patient's medical condition during the hospital course, and how was physical therapy utilized to achieve these results?
Reference answer: During the hospital course, the patient's medical condition improved significantly, with his breathing frequency decreasing and oxygen saturation returning to normal limits. Physical therapy was utilized with a regimen that included positioning, deep-breathing exercises, and walking. The patient was guided to achieve a prone position resulting in a significant increase in oxygen saturation from 88% to 96%.
For Asclepius summarization in our benchmark, every row is clinical note + grounded question → short answer. Evaluation always compares the model’s answer to the dataset answer in that same Q&A context (ROUGE vs reference text; Gemini judge against note + reference). ROUGE alone is not enough for clinical safety: a model can mention prone positioning and 88%→96% saturation and still hallucinate a treatment or misstate the mechanism—overlap can look fine while the judge flags clinical error.
MTSamples: Transcription Compression
Input transcription (abbreviated):
SUBJECTIVE: This 23-year-old white female presents with complaint of allergies. She used to have allergies when she lived in Seattle but she thinks they are worse here. In the past, she has tried Claritin, and Zyrtec. Both worked for short time but then seemed to lose effectiveness. She has used Allegra also... OBJECTIVE: Vitals: Weight was 130 pounds and blood pressure 124/78. HEENT: Her throat was mildly erythematous without exudate. Nasal mucosa was erythematous and swollen... ASSESSMENT: Allergic rhinitis. PLAN: 1. She will try Zyrtec instead of Allegra again... 2. Samples of Nasonex two sprays in each nostril given for three weeks
SUBJECTIVE: This 23-year-old white female presents with complaint of allergies. She used to have allergies when she lived in Seattle but she thinks they are worse here. In the past, she has tried Claritin, and Zyrtec. Both worked for short time but then seemed to lose effectiveness. She has used Allegra also... OBJECTIVE: Vitals: Weight was 130 pounds and blood pressure 124/78. HEENT: Her throat was mildly erythematous without exudate. Nasal mucosa was erythematous and swollen... ASSESSMENT: Allergic rhinitis. PLAN: 1. She will try Zyrtec instead of Allegra again... 2. Samples of Nasonex two sprays in each nostril given for three weeks
SUBJECTIVE: This 23-year-old white female presents with complaint of allergies. She used to have allergies when she lived in Seattle but she thinks they are worse here. In the past, she has tried Claritin, and Zyrtec. Both worked for short time but then seemed to lose effectiveness. She has used Allegra also... OBJECTIVE: Vitals: Weight was 130 pounds and blood pressure 124/78. HEENT: Her throat was mildly erythematous without exudate. Nasal mucosa was erythematous and swollen... ASSESSMENT: Allergic rhinitis. PLAN: 1. She will try Zyrtec instead of Allegra again... 2. Samples of Nasonex two sprays in each nostril given for three weeks
Reference (description field): Allergic Rhinitis
The description field is a short reference summary in the dataset — in this case a concise diagnostic label or clinical summary (e.g. "Allergic Rhinitis" for this row). A good model compresses the detailed dictation to the essential clinical picture without fabricating diagnoses or dropping relevant context. ROUGE scoring against a short reference is a strict lexical bar; the LLM judge evaluates whether the summary is clinically accurate and appropriately concise even when overlap scores are modest.
Syntech Triage: Urgency Classification
Three representative cases from the benchmark:
Case MTG-00001
Patient: Male, 66 years old
Symptoms: blurred vision, chest pain | Duration: 1 week | Onset: gradual
Red flags: blurred vision, chest pain
Gold label: Immediate
Case MTG-00002
Patient: Female, 12 years old
Symptoms: diarrhea, dizziness, rash | Duration: 1 day
Red flags: none
Gold label: Urgent
Case MTG-00003
Patient: Male, 4 years old
Symptoms: blurred vision, fever | Duration: 3 days | Context: while walking
Red flags: blurred vision
Gold label: Urgent
The model receives a short vignette from these fields and must respond with exactly one word: Immediate, Urgent, Semi-urgent, or Non-urgent. No chain of thought. Accuracy is a clean match or no-match against the dataset reference label.
Africa ED Triage: Cross-Population Validation
Each row in the Africa dataset (informal_triage split) carries structured fields including age, sex, patient type, true_acuity (the reference label), GCS, TEWS score, mobility, vital signs status, and disposition. Rows with triage_performed = 1 are kept. The model outputs an acuity label and is scored against true_acuity for that row — labels include values such as standard, very_urgent, and non_urgent (not a fixed four-colour scale).
A representative row: male, 36 years old, pediatric presentation, true acuity standard, with triage accuracy flagged as overtriage in the dataset metadata. This is a synthetic dataset modeling emergency triage system performance across Sub-Saharan African healthcare scenarios, capturing undertriage/overtriage, assigned vs true acuity, wait times, and mortality outcomes. See the dataset card for full provenance and methodology.
Quality Evaluation: Multi-Layer, Not ROUGE-Only
Clinical benchmarking with a single metric is dangerous. High lexical overlap does not mean clinical correctness. High classification accuracy on easy cases does not mean the model handles edge cases well. Our quality stack uses four complementary layers:
Layer 1 — ROUGE (Summarization)
ROUGE-1 and ROUGE-L measure lexical overlap between model output and reference answer. Fast, stable, good for regression tracking across runs. Deliberately used as a necessary but not sufficient signal — it catches obvious failures but cannot detect fluent hallucinations.
Layer 2 — LLM-as-Judge (Summarization)
A Gemini judge evaluates each summarization output on a rubric covering: key facts present, clinical accuracy, hallucinations, conciseness, and overall quality (1–5 scale). The overall_pct is derived and averaged to avg_judge_score per task and phase. This is the layer that catches what ROUGE misses — a fabricated medication, a wrong outcome, a missed intervention.
Why both: The methodology document states it explicitly — high overlap ≠ clinical correctness. The judge catches fabricated or unsafe content that ROUGE scores positively.
Layer 3 — Triage Accuracy
For Syntech and Africa ED: accuracy vs gold label after normalization (aliases, casing, first-token extraction). Clean match / no-match per row. No partial credit for "close" urgency calls — in triage, close is not acceptable.
The Results
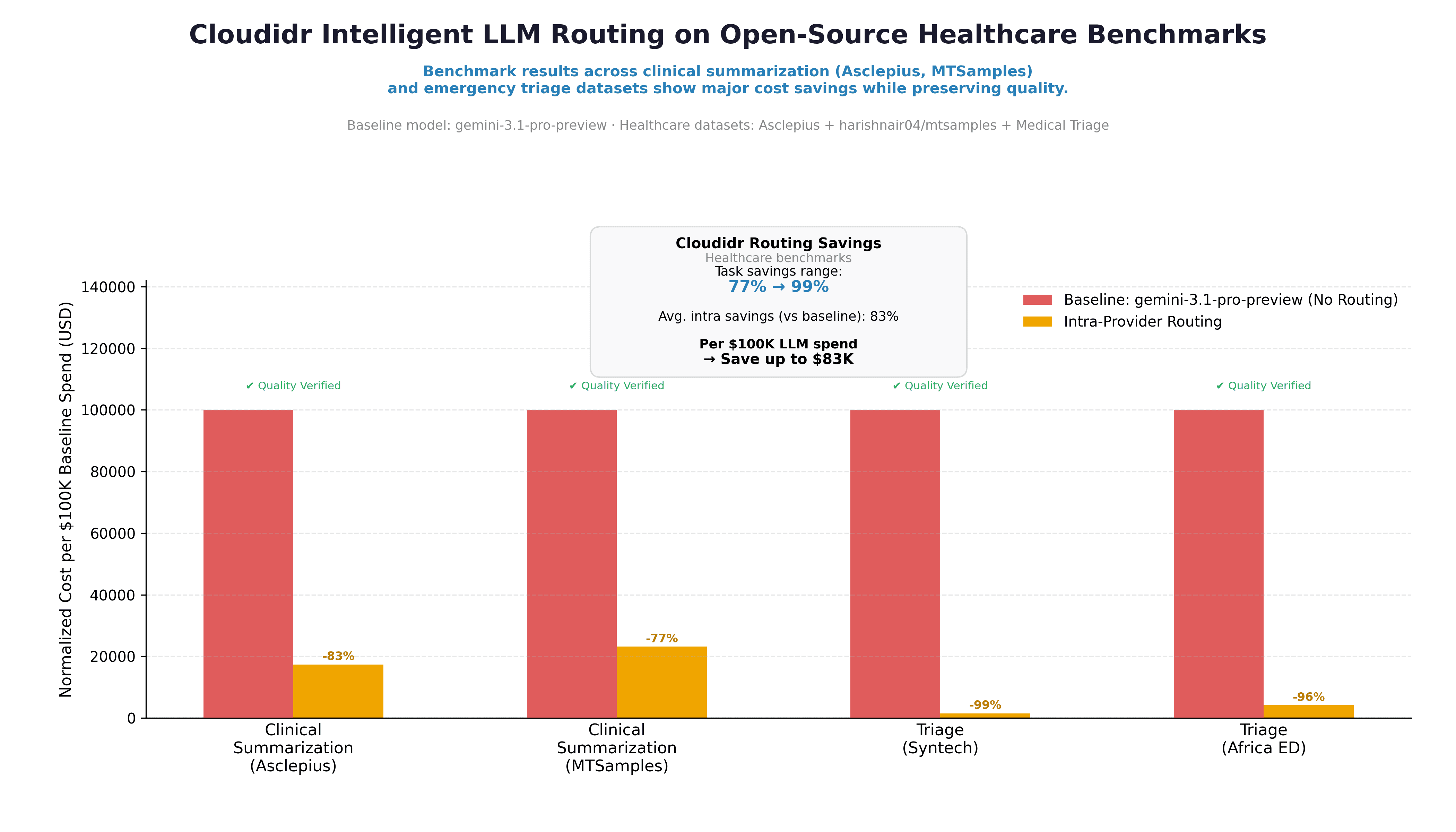
Baseline model: gemini-3.1-pro-preview (no routing) — every request sent to this model regardless of complexity Routed phase: Intra-provider routing — the Cloudidr routing engine redirects simpler prompts to lighter, cheaper models within the Google Gemini family, such as gemini-2.5-flash or gemini-3.1-flash-lite etc., while reserving the premium model for prompts that require it
All cost figures are normalized to cost per $100K of baseline spend so tasks on different absolute scales sit on the same axis.
Task | Baseline | Routed | Savings | Quality |
|---|---|---|---|---|
Clinical Summarization (Asclepius) | $100K | ~$17K | -83% | ✅ Verified |
Clinical Summarization (MTSamples) | $100K | ~$23K | -77% | ✅ Verified |
Triage (Syntech) | $100K | ~$1K | -99% | ✅ Verified |
Triage (Africa ED) | $100K | ~$4K | -96% | ✅ Verified |
Blended intra-provider savings: 83% vs baseline Per $100K LLM spend → save up to $83K Task savings range: 77% → 99%
The chart shows "Quality Verified" on every task group. In our run, quality checks passed across all four tasks — the numeric results below reflect that evaluation.
The triage results (99% and 96% savings) are particularly striking. For short, structured classification tasks, a significantly cheaper model within the same provider family matches the premium model's accuracy — the routing engine identifies this and routes accordingly. The summarization tasks show more modest but still substantial savings (77–83%) because the complexity distribution in clinical notes warrants more premium model usage than simple classification.
What This Means for Healthcare Teams
For summarization workloads: Intelligent routing can cut costs by 77–83% on clinical note summarization without degrading clinical accuracy — as validated by both lexical overlap and LLM judge scoring on actual clinical content. Not every note requires the most capable model. Routing matches the model to the note's complexity.
For triage support workloads: Short urgency classification tasks are strong candidates for aggressive routing — the benchmark shows 96–99% cost reduction with quality maintained. The key is the regression gate: savings are only reported when quality holds.
On open-source vs top providers: The benchmark above uses intra-provider routing (within the Google Gemini family). The Cloudidr platform also supports routing to managed open-source models — Llama, Qwen, Gemma — for teams with data sovereignty requirements or cost targets that commercial APIs cannot meet. The same quality evaluation framework applies regardless of which models are in the routing pool.
On reproducibility: All four datasets are public on Hugging Face.
Configuring Cloudidr LLM Ops for Clinical Workloads
If you're running clinical summarization or triage workloads and want to replicate these results in production, three configuration steps are all it takes.
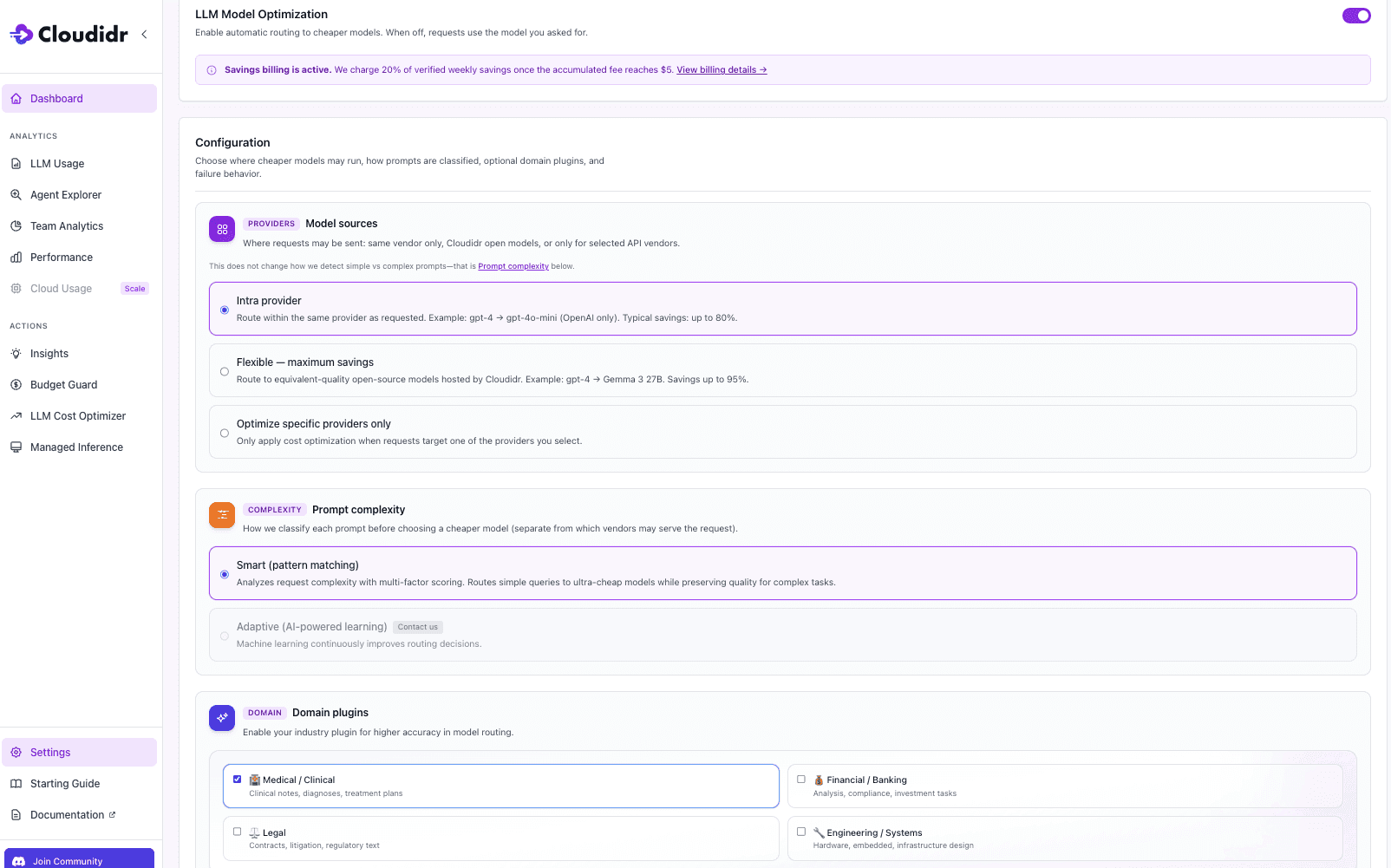
Step 1 — Enable LLM Model Optimization Toggle LLM Model Optimization on in your LLM Cost Optimizer settings. When off, every request goes to the model you specified with no routing applied. When on, the routing engine evaluates each prompt and selects the most cost-effective model that meets the quality threshold for that task.
Step 2 — Set Model Sources to Intra-Provider Select Intra-provider under Model Sources. This routes within the same provider family — for example, gemini-3.1-pro-preview routes simpler prompts to gemini-2.5-flash or gemini-3.1-flash-liteetc, while complex clinical notes continue to use the premium model. This is exactly the configuration used in the healthcare benchmark above. Typical savings up to 80%, entirely within your existing provider relationship with no new accounts or API keys required.
Step 3 — Enable the Medical / Clinical Domain Plugin Under Domain Plugins, check Medical / Clinical. This enables domain-aware complexity scoring for clinical notes, diagnoses, and treatment plans. For healthcare workloads this step will big gains — without it, the routing engine treats clinical content as general-purpose text and may under-route complex notes or over-route sensitive triage prompts. With it enabled, the engine applies clinical vocabulary and structure signals when deciding which model tier a prompt warrants.
Once active, go to the side panel and open LLM Cost Optimizer , which fully documents per-agent savings, original cost vs actual cost, and savings percentage across your clinical workloads in real time.
About This Benchmark
These benchmarks use public datasets for research and engineering comparison. They demonstrate the cost and quality characteristics of intelligent model routing on representative clinical tasks — they are not a substitute for clinical validation, IRB-approved studies, or your institution's clinical governance process. Always align LLM deployment in healthcare settings with HIPAA, applicable privacy regulations, and your institution's clinical safety requirements.
Start Routing Your Clinical Workloads
Cloudidr's LLM Ops platform brings intelligent model routing, real-time cost visibility, and budget controls to production LLM traffic — including healthcare workloads across OpenAI, Anthropic, Google Gemini, and AWS Bedrock.
→ Explore the platform → Book a demo → Read the AI FinOps blog → See the full LLM pricing comparison
Datasets referenced:
Asclepius Synthetic Clinical Notes: huggingface.co/datasets/starmpcc/Asclepius-Synthetic-Clinical-Notes
Syntech Medical Triage 500: huggingface.co/datasets/syntech-ai/medical-triage-500
Africa Emergency Triage: huggingface.co/datasets/electricsheepafrica/emergency-triage-systems
TL;DR
In our benchmark run, we measured 77–99% cost savings across clinical summarization and ED triage tasks using intelligent model routing — with quality checks passing on every task. Teams without a routing layer are likely leaving similar savings on the table, but your numbers will depend on your provider, model mix, and traffic distribution.
We benchmarked Cloudidr's intelligent model routing on four public clinical datasets: two summarization tasks (Asclepius synthetic clinical notes and MTSamples transcriptions) and two emergency triage tasks (Syntech and Africa ED). The baseline was gemini-3.1-pro-preview with no routing. The routed phase used intra-provider routing — staying within the same provider family.
Results: 77–99% cost savings across all four tasks. Costs are measured from tagged benchmark traffic; quality is evaluated on the same runs as a parallel track via ROUGE, LLM-as-judge scoring, and triage accuracy. Per $100K of LLM spend, our run showed savings up to $83K. Quality checks passed on every task.
The rest of this post covers exactly how we measured that — datasets, data examples, quality methodology, and results in full. All four datasets used are public on Hugging Face — links at the bottom of this post.
The Healthcare LLM Dilemma
Healthcare teams are under more pressure than ever to deploy LLMs for clinical documentation, summarization, and triage support — but two concerns slow every conversation: quality and cost.
Quality because the stakes are high. A hallucinated lab value, a missed urgency flag, a compressed note that drops a critical intervention — these are not software bugs, they are patient safety concerns. Quality evaluation in healthcare AI cannot be "does the output look reasonable." It needs to be grounded in clinical reference standards.
Cost because API spend on frontier models scales fast. A hospital system running clinical summarization across thousands of discharge notes per day on a premium model is spending significantly more than it needs to — and most teams have no visibility into whether a cheaper model could do the same job at the same quality level.
Cloudidr's intelligent model routing addresses both. This post benchmarks routing across four public clinical datasets — two summarization tasks and two emergency triage tasks — and reports cost savings alongside clinically grounded quality evaluation. The goal is a transparent, reproducible story: open datasets, documented methodology, and a quality gate that ensures savings are not "cheap at the price of safety."
The Four Datasets — What We Used and Why
We chose two summarization datasets and two triage datasets deliberately. Together they cover the two most common high-value LLM use cases in clinical settings, and they stress-test different model behaviors.
Summarization Pair
Asclepius — Synthetic Clinical Notes (starmpcc/Asclepius-Synthetic-Clinical-Notes)
Structured hospital course notes with a reference answer. Ideal for testing coherence and clinical detail on long-form notes — ICU admissions, surgical courses, and complex medical hospitalizations.
MTSamples — Medical Transcriptions (harishnair04/mtsamples)
Realistic clinical dictation transcriptions across multiple specialties — allergy, orthopedics, cardiology, and more. The transcription field (often long dictation-style notes spanning multiple sections) is the input; the description field provides a short reference summary the model output is scored against. This creates a demanding compression task: the model must distill rich clinical detail down to the essential presenting problem without losing relevant information.
The two datasets complement each other deliberately. Asclepius evaluates whether a model can answer a specific clinical question about a hospital course with accuracy. MTSamples evaluates whether a model can compress a dense transcription into a concise summary — a different skill, and a harder one to fake.
Triage Pair
Syntech Medical Triage 500 (syntech-ai/medical-triage-500)
Structured clinical vignettes with patient demographics, symptom presentation, duration, onset, context, and red flags. Each case carries a reference label (urgency_category): Immediate, Urgent, Semi-urgent, or Non-urgent. Note that Syntech is a fully synthetic dataset created for AI prototyping and triage classification research — not clinical records. The model receives a short vignette prompt and must answer with one of those four labels — no reasoning, no hedging. Accuracy is measured against the dataset's reference label.
Africa Emergency Triage System (electricsheepafrica/emergency-triage-systems)
Emergency triage scenarios from African healthcare contexts, covering a different patient population, clinical vocabulary, and triage schema. Each row carries a true_acuity label used as the gold standard. This dataset complements Syntech by testing whether routing quality holds across different geographies and clinical settings — not just Western hospital presentations.
The two triage datasets together test whether a routed model maintains classification accuracy on high-stakes, short-output tasks across diverse populations. A wrong urgency call — Non-urgent when the case is Immediate — is a meaningful error, and the quality gate reflects that.
The Data in Practice — What the Models Are Actually Evaluating
Asclepius: Hospital Course Summarization
Here is a representative Asclepius row — the shape of data the models process in the summarization benchmark:
Input note (abbreviated):
Hospital Course Summary: Patient: Male, Age 57 Admission Diagnosis: Oxygen Desaturation The patient was admitted to the ICU one week after a positive COVID-19 result due to oxygen desaturation. Physical therapy was initiated promptly after admission, which helped improve the patient's breathing frequency and oxygen saturation. The patient was guided to achieve a prone position resulting in a significant increase in oxygen saturation from 88% to 96%... After three days with this regime, the patient was transferred to the normal ward. After nine days from ICU admission, the patient was successfully discharged from the hospital as a pedestrian
Question: What were the key improvements in the patient's medical condition during the hospital course, and how was physical therapy utilized to achieve these results?
Reference answer: During the hospital course, the patient's medical condition improved significantly, with his breathing frequency decreasing and oxygen saturation returning to normal limits. Physical therapy was utilized with a regimen that included positioning, deep-breathing exercises, and walking. The patient was guided to achieve a prone position resulting in a significant increase in oxygen saturation from 88% to 96%.
For Asclepius summarization in our benchmark, every row is clinical note + grounded question → short answer. Evaluation always compares the model’s answer to the dataset answer in that same Q&A context (ROUGE vs reference text; Gemini judge against note + reference). ROUGE alone is not enough for clinical safety: a model can mention prone positioning and 88%→96% saturation and still hallucinate a treatment or misstate the mechanism—overlap can look fine while the judge flags clinical error.
MTSamples: Transcription Compression
Input transcription (abbreviated):
SUBJECTIVE: This 23-year-old white female presents with complaint of allergies. She used to have allergies when she lived in Seattle but she thinks they are worse here. In the past, she has tried Claritin, and Zyrtec. Both worked for short time but then seemed to lose effectiveness. She has used Allegra also... OBJECTIVE: Vitals: Weight was 130 pounds and blood pressure 124/78. HEENT: Her throat was mildly erythematous without exudate. Nasal mucosa was erythematous and swollen... ASSESSMENT: Allergic rhinitis. PLAN: 1. She will try Zyrtec instead of Allegra again... 2. Samples of Nasonex two sprays in each nostril given for three weeks
Reference (description field): Allergic Rhinitis
The description field is a short reference summary in the dataset — in this case a concise diagnostic label or clinical summary (e.g. "Allergic Rhinitis" for this row). A good model compresses the detailed dictation to the essential clinical picture without fabricating diagnoses or dropping relevant context. ROUGE scoring against a short reference is a strict lexical bar; the LLM judge evaluates whether the summary is clinically accurate and appropriately concise even when overlap scores are modest.
Syntech Triage: Urgency Classification
Three representative cases from the benchmark:
Case MTG-00001
Patient: Male, 66 years old
Symptoms: blurred vision, chest pain | Duration: 1 week | Onset: gradual
Red flags: blurred vision, chest pain
Gold label: Immediate
Case MTG-00002
Patient: Female, 12 years old
Symptoms: diarrhea, dizziness, rash | Duration: 1 day
Red flags: none
Gold label: Urgent
Case MTG-00003
Patient: Male, 4 years old
Symptoms: blurred vision, fever | Duration: 3 days | Context: while walking
Red flags: blurred vision
Gold label: Urgent
The model receives a short vignette from these fields and must respond with exactly one word: Immediate, Urgent, Semi-urgent, or Non-urgent. No chain of thought. Accuracy is a clean match or no-match against the dataset reference label.
Africa ED Triage: Cross-Population Validation
Each row in the Africa dataset (informal_triage split) carries structured fields including age, sex, patient type, true_acuity (the reference label), GCS, TEWS score, mobility, vital signs status, and disposition. Rows with triage_performed = 1 are kept. The model outputs an acuity label and is scored against true_acuity for that row — labels include values such as standard, very_urgent, and non_urgent (not a fixed four-colour scale).
A representative row: male, 36 years old, pediatric presentation, true acuity standard, with triage accuracy flagged as overtriage in the dataset metadata. This is a synthetic dataset modeling emergency triage system performance across Sub-Saharan African healthcare scenarios, capturing undertriage/overtriage, assigned vs true acuity, wait times, and mortality outcomes. See the dataset card for full provenance and methodology.
Quality Evaluation: Multi-Layer, Not ROUGE-Only
Clinical benchmarking with a single metric is dangerous. High lexical overlap does not mean clinical correctness. High classification accuracy on easy cases does not mean the model handles edge cases well. Our quality stack uses four complementary layers:
Layer 1 — ROUGE (Summarization)
ROUGE-1 and ROUGE-L measure lexical overlap between model output and reference answer. Fast, stable, good for regression tracking across runs. Deliberately used as a necessary but not sufficient signal — it catches obvious failures but cannot detect fluent hallucinations.
Layer 2 — LLM-as-Judge (Summarization)
A Gemini judge evaluates each summarization output on a rubric covering: key facts present, clinical accuracy, hallucinations, conciseness, and overall quality (1–5 scale). The overall_pct is derived and averaged to avg_judge_score per task and phase. This is the layer that catches what ROUGE misses — a fabricated medication, a wrong outcome, a missed intervention.
Why both: The methodology document states it explicitly — high overlap ≠ clinical correctness. The judge catches fabricated or unsafe content that ROUGE scores positively.
Layer 3 — Triage Accuracy
For Syntech and Africa ED: accuracy vs gold label after normalization (aliases, casing, first-token extraction). Clean match / no-match per row. No partial credit for "close" urgency calls — in triage, close is not acceptable.
The Results
Baseline model: gemini-3.1-pro-preview (no routing) — every request sent to this model regardless of complexity Routed phase: Intra-provider routing — the Cloudidr routing engine redirects simpler prompts to lighter, cheaper models within the Google Gemini family, such as gemini-2.5-flash or gemini-3.1-flash-lite etc., while reserving the premium model for prompts that require it
All cost figures are normalized to cost per $100K of baseline spend so tasks on different absolute scales sit on the same axis.
Task | Baseline | Routed | Savings | Quality |
|---|---|---|---|---|
Clinical Summarization (Asclepius) | $100K | ~$17K | -83% | ✅ Verified |
Clinical Summarization (MTSamples) | $100K | ~$23K | -77% | ✅ Verified |
Triage (Syntech) | $100K | ~$1K | -99% | ✅ Verified |
Triage (Africa ED) | $100K | ~$4K | -96% | ✅ Verified |
Blended intra-provider savings: 83% vs baseline Per $100K LLM spend → save up to $83K Task savings range: 77% → 99%
The chart shows "Quality Verified" on every task group. In our run, quality checks passed across all four tasks — the numeric results below reflect that evaluation.
The triage results (99% and 96% savings) are particularly striking. For short, structured classification tasks, a significantly cheaper model within the same provider family matches the premium model's accuracy — the routing engine identifies this and routes accordingly. The summarization tasks show more modest but still substantial savings (77–83%) because the complexity distribution in clinical notes warrants more premium model usage than simple classification.
What This Means for Healthcare Teams
For summarization workloads: Intelligent routing can cut costs by 77–83% on clinical note summarization without degrading clinical accuracy — as validated by both lexical overlap and LLM judge scoring on actual clinical content. Not every note requires the most capable model. Routing matches the model to the note's complexity.
For triage support workloads: Short urgency classification tasks are strong candidates for aggressive routing — the benchmark shows 96–99% cost reduction with quality maintained. The key is the regression gate: savings are only reported when quality holds.
On open-source vs top providers: The benchmark above uses intra-provider routing (within the Google Gemini family). The Cloudidr platform also supports routing to managed open-source models — Llama, Qwen, Gemma — for teams with data sovereignty requirements or cost targets that commercial APIs cannot meet. The same quality evaluation framework applies regardless of which models are in the routing pool.
On reproducibility: All four datasets are public on Hugging Face.
Configuring Cloudidr LLM Ops for Clinical Workloads
If you're running clinical summarization or triage workloads and want to replicate these results in production, three configuration steps are all it takes.
Step 1 — Enable LLM Model Optimization Toggle LLM Model Optimization on in your LLM Cost Optimizer settings. When off, every request goes to the model you specified with no routing applied. When on, the routing engine evaluates each prompt and selects the most cost-effective model that meets the quality threshold for that task.
Step 2 — Set Model Sources to Intra-Provider Select Intra-provider under Model Sources. This routes within the same provider family — for example, gemini-3.1-pro-preview routes simpler prompts to gemini-2.5-flash or gemini-3.1-flash-liteetc, while complex clinical notes continue to use the premium model. This is exactly the configuration used in the healthcare benchmark above. Typical savings up to 80%, entirely within your existing provider relationship with no new accounts or API keys required.
Step 3 — Enable the Medical / Clinical Domain Plugin Under Domain Plugins, check Medical / Clinical. This enables domain-aware complexity scoring for clinical notes, diagnoses, and treatment plans. For healthcare workloads this step will big gains — without it, the routing engine treats clinical content as general-purpose text and may under-route complex notes or over-route sensitive triage prompts. With it enabled, the engine applies clinical vocabulary and structure signals when deciding which model tier a prompt warrants.
Once active, go to the side panel and open LLM Cost Optimizer , which fully documents per-agent savings, original cost vs actual cost, and savings percentage across your clinical workloads in real time.
About This Benchmark
These benchmarks use public datasets for research and engineering comparison. They demonstrate the cost and quality characteristics of intelligent model routing on representative clinical tasks — they are not a substitute for clinical validation, IRB-approved studies, or your institution's clinical governance process. Always align LLM deployment in healthcare settings with HIPAA, applicable privacy regulations, and your institution's clinical safety requirements.
Start Routing Your Clinical Workloads
Cloudidr's LLM Ops platform brings intelligent model routing, real-time cost visibility, and budget controls to production LLM traffic — including healthcare workloads across OpenAI, Anthropic, Google Gemini, and AWS Bedrock.
→ Explore the platform → Book a demo → Read the AI FinOps blog → See the full LLM pricing comparison
Datasets referenced:
Asclepius Synthetic Clinical Notes: huggingface.co/datasets/starmpcc/Asclepius-Synthetic-Clinical-Notes
Syntech Medical Triage 500: huggingface.co/datasets/syntech-ai/medical-triage-500
Africa Emergency Triage: huggingface.co/datasets/electricsheepafrica/emergency-triage-systems
Explore More from Cloudidr ...
Explore More from Cloudidr ...
Explore More from Cloudidr ...
Explore More from Cloudidr ...
Smarter Model Routing for Clinical Summarization and ED Triage: What We Benchmarked and What We Saved
Smarter Model Routing for Clinical Summarization and ED Triage: What We Benchmarked and What We Saved
AI FinOps: The New Discipline Every AI-First Company Needs
AI FinOps: The New Discipline Every AI-First Company Needs
How Intelligent Model Routing Cuts Financial AI Costs by 37–89%: A Real Benchmark
How Intelligent Model Routing Cuts Financial AI Costs by 37–89%: A Real Benchmark
Load More
Load More


Backed by

Backed by
Backed by