LLM Ops
Published on:
Khursheed Hassan

You did countless iterations and shipped the Gen AI feature that your users love. You are over the moon. Then your CEO and finance gets the API bill. Uncontrolled LLM API spend has rapidly become the most unpredictable line item in enterprise IT.
Uncontrolled LLM spend has quietly become the most unpredictable line item in enterprise technology budgets — not because the technology is broken, but because nobody built the right infrastructure around it.
When organizations move AI from sandbox to production, they hit a cost governance wall almost immediately.
Engineering teams reach for expensive premium models by default, because those models are reliable and nobody told them not to. Finance has no idea which product, team, or developer is driving the spend. A runaway logic loop can rack up thousands of dollars before anyone notices.
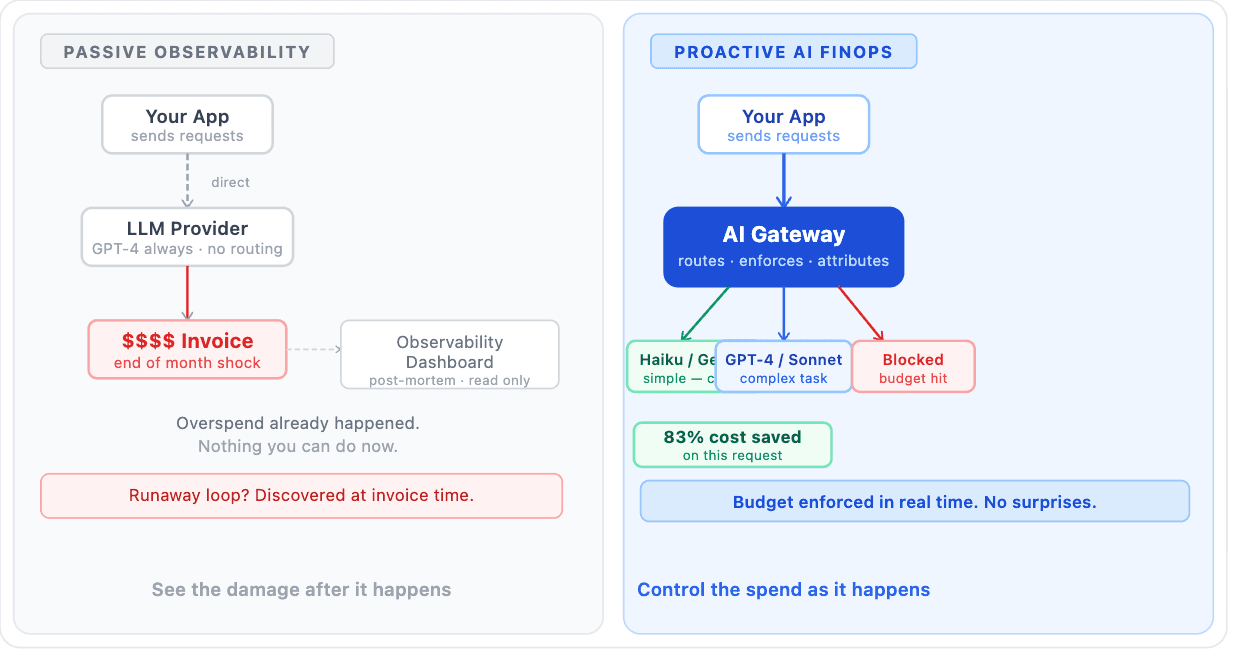
The market's response has largely been to add more observability tooling. But seeing the bill is not the same as controlling it. What enterprises actually need is a fundamental shift in how AI infrastructure is managed — proactive AI FinOps, not passive logging.
The Gap Between Observability and Cost Action
Traditional LLM observability platforms were built for debugging. They excel at tracing latency, analyzing prompt performance, and identifying hallucinations. When it comes to cost, they offer post-mortem dashboards.
Telling a FinOps practitioner that a specific prompt chain cost $4,000 last week is interesting, but it isn’t actionable. Proactive governance looks different. Finance and engineering leaders need hard budget guardrails that prevent overspend before it happens. They need granular cost attribution broken down by team, project, and model. And they need the ability to optimize spend at the infrastructure level without asking developers to rewrite applications or manage complex failover logic.
This is the gap in the market. Enterprises need a control plane for AI spend that actually controls the spend.
Developer-Lite: Why Integration Speed Matters
The biggest barrier to implementing cost controls is engineering friction. If an optimization tool requires deep architectural changes, complex SDK integrations, or heavy maintenance, platform teams will reject it. They are evaluated on shipping features, not building FinOps plumbing.
Cloudidr was designed around a "developer-lite" philosophy. The platform acts as a secure, real-time control plane that requires zero architectural changes.
Engineering teams can integrate the AI FinOps platform in 60 seconds with just two lines of code. There are no proxies to manage and no complex networking configurations to maintain.
Crucially, this architecture respects enterprise security boundaries. Cloudidr never stores LLM API keys. Customers maintain their direct billing relationships, retaining any negotiated enterprise discounts with their LLM providers.
This approach stems directly from our experience in building massive-scale infrastructure - the lesson is; infrastructure governance only works if it is frictionless for the developers using it.
Cutting LLM Costs Up to 90% via Intelligent Routing
The most common cause of LLM API waste is the over-reliance on premium models. Developers often hardcode calls to GPT-5 or Claude 4.6 Sonnet because they are reliable, even when the task is simple data extraction, formatting, or basic summarization.
Cloudidr solves this through intelligent model routing. Instead of hardcoding a specific model, applications send the request to Cloudidr, which evaluates the prompt in real time.
The platform instantly routes every LLM request to the cheapest capable model across OpenAI, Anthropic, Google Gemini, and AWS Bedrock (it works natively with Bedrock and routes across the models available in there). If a cheaper, faster model can achieve the required quality threshold for a specific prompt, the request is dynamically redirected.
This happens seamlessly. The intelligent routing adds on avg 8-20ms of latency (vs 10,000-20,000 from overall network end to end lateniecs), making it invisible to the end user while fundamentally changing the unit economics of the application.
The Healthcare Benchmark
The impact of intelligent routing isn't theoretical. In our internal healthcare benchmark, we evaluated workloads across clinical summarization and patient triage.
The baseline strategy utilized exclusively premium models. By implementing Cloudidr’s intelligent routing, the system dynamically evaluated complexity and routed tasks accordingly. The results were immediate:
* 77–99% cost savings per individual task.
* ~83% blended savings across the entire workload.
* Roughly $83K saved per $100K of baseline LLM spend.
Most importantly, this 83% cost reduction was achieved while maintaining strict clinical quality standards. The application delivered the exact same user experience, but the infrastructure cost was optimized at the request level.
Hard Budget Controls and True Attribution
Beyond dynamic routing, a mature AI FinOps platform must provide strict financial governance.
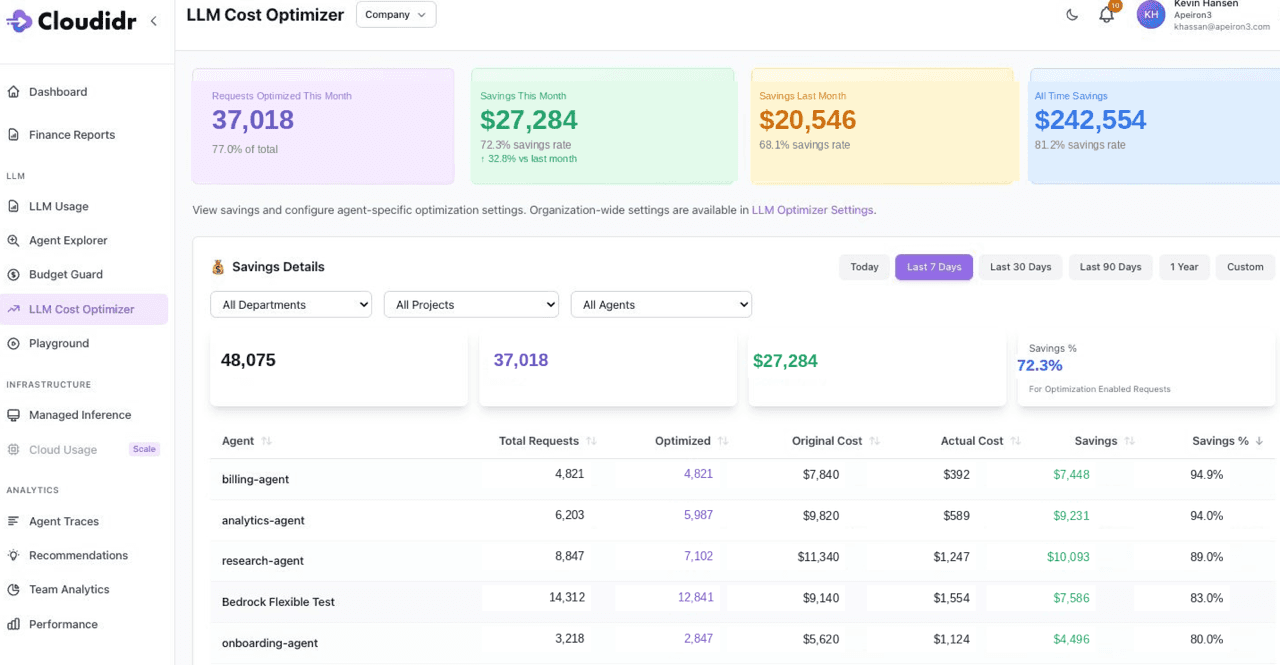
Cloudidr gives finance teams full visibility into every dollar spent on AI. Instead of a massive, opaque monthly invoice from frontier model providers or AWS, organizations get real-time attribution broken down by specific engineering teams, individual projects, and exact models used.
This visibility is paired with hard budget controls. Platform leads can set strict spend limits on specific projects or sandbox environments. If a developer accidentally deploys a runaway loop that generates thousands of API calls, Cloudidr intercepts and halts the traffic the moment it hits the predefined budget threshold.
This eliminates the "API shock" at the end of the month and empowers finance teams to forecast AI unit economics accurately.
Moving AI FinOps from Concept to Production
The generative AI stack is maturing. We are moving past the era where unpredictable API bills were simply the cost of doing business.
Building sustainable AI products requires infrastructure that balances performance, security, and unit economics. Developers need the freedom to build without worrying about complex routing logic, and finance needs the assurance that API budgets won't spiral out of control.
Stop treating your LLM API spend as an uncontrollable black box. Gain visibility, implement hard budget guardrails, and start optimizing your traffic today.
Visit cloudidr.com to see how our developer-lite AI FinOps platform can cut your LLM costs by up to 90% in under 60 seconds. Or, reach out to me we, you will be thousands literally within minutes.




