LLM Ops
How We Slashed Inference Costs by 80% with Managed Gemma 4 31B
How We Slashed Inference Costs by 80% with Managed Gemma 4 31B
How We Slashed Inference Costs by 80% with Managed Gemma 4 31B
How We Slashed Inference Costs by 80% with Managed Gemma 4 31B
Published on:
Cloudidr Tram

You don’t need a Ferrari to pick up groceries. Yet, engineering teams routinely burn hundreds of thousands of dollars running basic extraction, classification, and summarization tasks through expensive premium models.
The reality of running large language models in production is that most tasks do not require frontier reasoning capabilities. As generative AI infrastructure matures, the secret to sustainable margins isn't negotiating better discounts with your LLM provider—it's routing workloads to the most efficient model capable of doing the job. (Source: a16z on Navigating the High Cost of AI Compute)
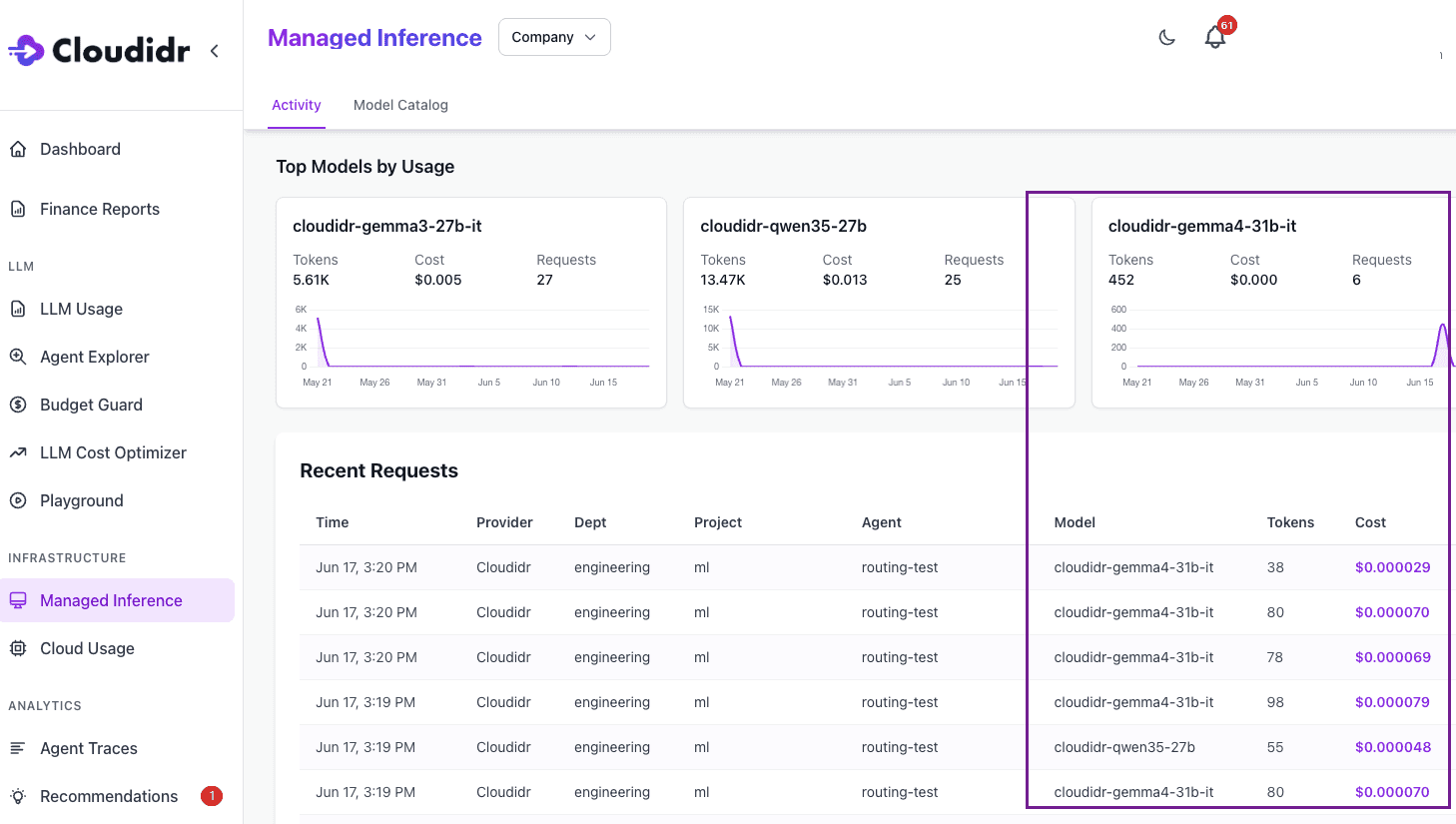
That is why we just launched Gemma 4 31B as a managed inference offering directly on Cloudidr LLM Ops. We built this to give engineering and FinOps teams a high-performance, low-cost routing target for high-volume workloads.
Here is exactly how it performs, what it costs, and how you can drop it into your stack with a single API endpoint.
The Economics of Open Weights vs. Closed APIs
When you scale AI features—especially autonomous agents that operate in continuous loops—inference costs compound aggressively.
Let's look at the current landscape for fast, capable "small" models. At scale, your primary financial drag is output tokens.
* Claude Haiku 4.5 charges $1.00 per 1M input tokens and $5.00 per 1M output tokens.
* GPT-5.4-mini charges $0.75 per 1M input tokens and $4.50 per 1M output tokens.
Managed Gemma 4 31B on Cloudidr costs $0.50 per 1M input and $1.00 per 1M output.
Compared to Haiku 4.5, that is 2× cheaper on input and a massive 5× cheaper on output. Compared to GPT-5.4-mini, it remains 1.5× cheaper on input and 4.5× cheaper on output.
If you are currently paying Haiku or GPT-5.4-mini prices for summarization, entity extraction, semantic routing, or high-volume agent workloads, your AI margins are bleeding unnecessarily. For these specific use cases, Gemma 4 31B is the model you should be routing to.
Why Gemma 4 31B?
Gemma 4 31B is a next-generation open model that punches significantly above its weight class. Google designed this architecture with production efficiency in mind. (Source: Google DeepMind Gemma Release Notes)
It features a massive 256K context window, native multimodal input capabilities, and built-in reasoning steps. Crucially, the model is quantization-aware trained. This means it maintains near-bf16 reasoning quality even when quantized for faster, cheaper inference hardware.
You get the nuance and instruction-following of a heavy frontier model with the latency profile of a highly optimized edge model.
Production Benchmarks: Built for Speed
Cost savings mean nothing if the model bottlenecks your user experience. Agentic loops require rapid generation to feel responsive. We benchmarked this managed offering heavily on our production infrastructure before launch.
Here is what you can expect when hitting the cloudidr-gemma4-31b-it endpoint:
* 52 TPS (Tokens Per Second) per user: This is fast enough for real-time voice streaming and instantaneous chat interfaces.
* 272 TPS average throughput: Built to handle concurrent enterprise workloads without queuing delays.
* 507 TPS peak throughput: Massive burst capacity to handle traffic spikes during batch processing or agent fan-out tasks.
Self-hosting a 31-billion parameter model to achieve these numbers is a massive operational headache. It requires managing complex KV cache configurations, dynamic batching, and elastic GPU provisioning. By using Cloudidr's managed endpoint, you offload the infrastructure completely.
One API Endpoint. Zero Ops Overhead.
The defining feature of Cloudidr is that we treat AI FinOps not as an observability afterthought, but as an active control plane.
Because this managed Gemma 4 31B model runs inside Cloudidr LLM Ops, you get full cost attribution, budget guardrails, and intelligent routing automatically applied to every request. There is no separate integration, no new SDKs to learn, and no ops overhead.
You can access it using your existing OpenAI-compatible SDKs or a simple REST call. Just change the base URL and pass your attribution headers.
Here is what the integration looks like:
curl https://api.llm-ops.cloudidr.com/v1/chat/completions \ -H "Content-Type: application/json" \ -H "X-Cloudidr-Key: trk_9H4V2BUsfKfklCfjLHbGjwnAlBYAEzpy" \ -H "X-Department: engineering" \ -H "X-Project: ml" \ -H "X-Agent: chatbot" \ -d '{ "model": "cloudidr-gemma4-31b-it", "messages": [{"role": "user", "content": "Hello!"}] }'
curl https://api.llm-ops.cloudidr.com/v1/chat/completions \ -H "Content-Type: application/json" \ -H "X-Cloudidr-Key: trk_9H4V2BUsfKfklCfjLHbGjwnAlBYAEzpy" \ -H "X-Department: engineering" \ -H "X-Project: ml" \ -H "X-Agent: chatbot" \ -d '{ "model": "cloudidr-gemma4-31b-it", "messages": [{"role": "user", "content": "Hello!"}] }'
curl https://api.llm-ops.cloudidr.com/v1/chat/completions \ -H "Content-Type: application/json" \ -H "X-Cloudidr-Key: trk_9H4V2BUsfKfklCfjLHbGjwnAlBYAEzpy" \ -H "X-Department: engineering" \ -H "X-Project: ml" \ -H "X-Agent: chatbot" \ -d '{ "model": "cloudidr-gemma4-31b-it", "messages": [{"role": "user", "content": "Hello!"}] }'
Notice the custom headers: X-Department, X-Project, and X-Agent. By simply including these in your standard API call, Cloudidr instantly categorizes the $0.50/$1.00 token spend.
Finance teams get granular visibility into exactly which agent, project, or department is driving AI costs. Engineering teams get hard budget guardrails that prevent a runaway script from draining the monthly cloud budget overnight. (Source: Gartner on Managing Generative AI Costs)
Stop Overpaying for Standard Workloads
Intelligent model routing is the highest-leverage action an engineering team can take to optimize their AI infrastructure.
If your application relies on high-volume data processing, document summarization, or chained agentic reasoning, pushing every request to Claude Haiku 4.5 or GPT-5.4-mini is leaving money on the table.
With managed Gemma 4 31B on Cloudidr, you get frontier-level speed, massive context windows, and automated FinOps governance—all while slashing your output token costs by up to 80%.
Ready to see how fast your workloads can run on Gemma 4? Update your base URL and start testing today at 👉 llm-ops.cloudidr.com.
You don’t need a Ferrari to pick up groceries. Yet, engineering teams routinely burn hundreds of thousands of dollars running basic extraction, classification, and summarization tasks through expensive premium models.
The reality of running large language models in production is that most tasks do not require frontier reasoning capabilities. As generative AI infrastructure matures, the secret to sustainable margins isn't negotiating better discounts with your LLM provider—it's routing workloads to the most efficient model capable of doing the job. (Source: a16z on Navigating the High Cost of AI Compute)
That is why we just launched Gemma 4 31B as a managed inference offering directly on Cloudidr LLM Ops. We built this to give engineering and FinOps teams a high-performance, low-cost routing target for high-volume workloads.
Here is exactly how it performs, what it costs, and how you can drop it into your stack with a single API endpoint.
The Economics of Open Weights vs. Closed APIs
When you scale AI features—especially autonomous agents that operate in continuous loops—inference costs compound aggressively.
Let's look at the current landscape for fast, capable "small" models. At scale, your primary financial drag is output tokens.
* Claude Haiku 4.5 charges $1.00 per 1M input tokens and $5.00 per 1M output tokens.
* GPT-5.4-mini charges $0.75 per 1M input tokens and $4.50 per 1M output tokens.
Managed Gemma 4 31B on Cloudidr costs $0.50 per 1M input and $1.00 per 1M output.
Compared to Haiku 4.5, that is 2× cheaper on input and a massive 5× cheaper on output. Compared to GPT-5.4-mini, it remains 1.5× cheaper on input and 4.5× cheaper on output.
If you are currently paying Haiku or GPT-5.4-mini prices for summarization, entity extraction, semantic routing, or high-volume agent workloads, your AI margins are bleeding unnecessarily. For these specific use cases, Gemma 4 31B is the model you should be routing to.
Why Gemma 4 31B?
Gemma 4 31B is a next-generation open model that punches significantly above its weight class. Google designed this architecture with production efficiency in mind. (Source: Google DeepMind Gemma Release Notes)
It features a massive 256K context window, native multimodal input capabilities, and built-in reasoning steps. Crucially, the model is quantization-aware trained. This means it maintains near-bf16 reasoning quality even when quantized for faster, cheaper inference hardware.
You get the nuance and instruction-following of a heavy frontier model with the latency profile of a highly optimized edge model.
Production Benchmarks: Built for Speed
Cost savings mean nothing if the model bottlenecks your user experience. Agentic loops require rapid generation to feel responsive. We benchmarked this managed offering heavily on our production infrastructure before launch.
Here is what you can expect when hitting the cloudidr-gemma4-31b-it endpoint:
* 52 TPS (Tokens Per Second) per user: This is fast enough for real-time voice streaming and instantaneous chat interfaces.
* 272 TPS average throughput: Built to handle concurrent enterprise workloads without queuing delays.
* 507 TPS peak throughput: Massive burst capacity to handle traffic spikes during batch processing or agent fan-out tasks.
Self-hosting a 31-billion parameter model to achieve these numbers is a massive operational headache. It requires managing complex KV cache configurations, dynamic batching, and elastic GPU provisioning. By using Cloudidr's managed endpoint, you offload the infrastructure completely.
One API Endpoint. Zero Ops Overhead.
The defining feature of Cloudidr is that we treat AI FinOps not as an observability afterthought, but as an active control plane.
Because this managed Gemma 4 31B model runs inside Cloudidr LLM Ops, you get full cost attribution, budget guardrails, and intelligent routing automatically applied to every request. There is no separate integration, no new SDKs to learn, and no ops overhead.
You can access it using your existing OpenAI-compatible SDKs or a simple REST call. Just change the base URL and pass your attribution headers.
Here is what the integration looks like:
curl https://api.llm-ops.cloudidr.com/v1/chat/completions \ -H "Content-Type: application/json" \ -H "X-Cloudidr-Key: trk_9H4V2BUsfKfklCfjLHbGjwnAlBYAEzpy" \ -H "X-Department: engineering" \ -H "X-Project: ml" \ -H "X-Agent: chatbot" \ -d '{ "model": "cloudidr-gemma4-31b-it", "messages": [{"role": "user", "content": "Hello!"}] }'
Notice the custom headers: X-Department, X-Project, and X-Agent. By simply including these in your standard API call, Cloudidr instantly categorizes the $0.50/$1.00 token spend.
Finance teams get granular visibility into exactly which agent, project, or department is driving AI costs. Engineering teams get hard budget guardrails that prevent a runaway script from draining the monthly cloud budget overnight. (Source: Gartner on Managing Generative AI Costs)
Stop Overpaying for Standard Workloads
Intelligent model routing is the highest-leverage action an engineering team can take to optimize their AI infrastructure.
If your application relies on high-volume data processing, document summarization, or chained agentic reasoning, pushing every request to Claude Haiku 4.5 or GPT-5.4-mini is leaving money on the table.
With managed Gemma 4 31B on Cloudidr, you get frontier-level speed, massive context windows, and automated FinOps governance—all while slashing your output token costs by up to 80%.
Ready to see how fast your workloads can run on Gemma 4? Update your base URL and start testing today at 👉 llm-ops.cloudidr.com.
Explore More from Cloudidr ...
Explore More from Cloudidr ...
Explore More from Cloudidr ...
Explore More from Cloudidr ...
How We Slashed Inference Costs by 80% with Managed Gemma 4 31B
How We Slashed Inference Costs by 80% with Managed Gemma 4 31B

The LLM API Tax — How Cloudidr's Developer-Lite AI FinOps Quickly Fixes LLM Spend
The LLM API Tax — How Cloudidr's Developer-Lite AI FinOps Quickly Fixes LLM Spend

Model Evaluation Should Be Easy — Cloudidr vs Braintrust, Helicone, and Portkey
Model Evaluation Should Be Easy — Cloudidr vs Braintrust, Helicone, and Portkey
Load More
Load More


Backed by

Backed by
Backed by