LLM Ops
Agent Tracing Without the Overhead — Cloudidr vs. LangSmith vs. Braintrust
Agent Tracing Without the Overhead — Cloudidr vs. LangSmith vs. Braintrust
Agent Tracing Without the Overhead — Cloudidr vs. LangSmith vs. Braintrust
Agent Tracing Without the Overhead — Cloudidr vs. LangSmith vs. Braintrust
Published on:
Cloudidr Team
Autonomous AI agents are fundamentally changing the math of cloud infrastructure. A single user prompt no longer equals a single API call. Instead, agents trigger reasoning loops, execute tool calls, retrieve memory context, and retry failures. A seemingly simple user request can easily spawn a dozen distinct calls to Anthropic or OpenAI, quietly burning through your API budget.
When agent spending spirals, engineering and finance teams face a shared mandate: you need to see exactly what these models are doing under the hood. You need agent tracing.
But how you trace your agents dictates whether you solve your cost problem or just create a new integration nightmare for your platform team. The market currently offers deep observability frameworks like LangSmith, evaluation tools like Braintrust, and AI FinOps platforms like Cloudidr.
Here is how these approaches compare, and why the simplest integration often yields the highest operational ROI.
The Problem with Agent Visibility
Tracing an AI agent isn't like monitoring a standard microservice. Agents are non-deterministic. A typical agent trace must capture the initial prompt, the LLM's decision to invoke an external tool, the tool's execution, the model's subsequent reasoning, and the final user-facing response.
According to Gartner's projections on generative AI, managing the cost and complexity of these multi-step generative workflows is the primary operational hurdle for enterprise AI deployment. If you can't trace the multi-step execution tree, you can't debug model hallucinations. More importantly, you cannot attribute costs to specific teams, projects, or users.
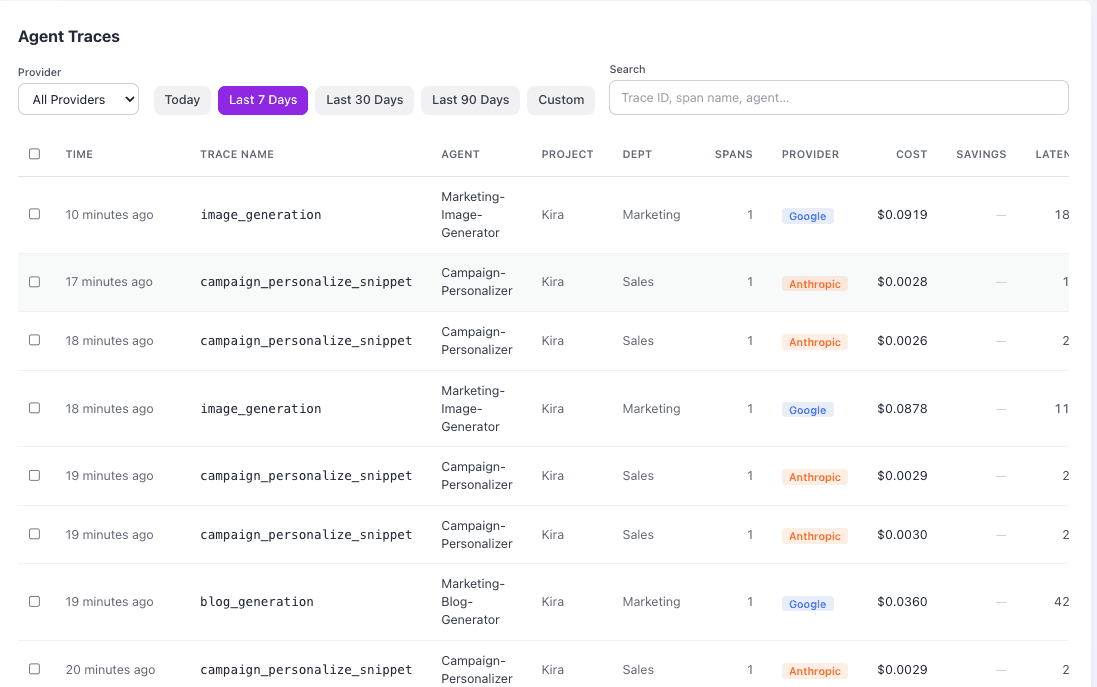
LangChain (LangSmith): The Ecosystem Heavyweight
LangSmith, built by the creators of LangChain, is a powerful observability tool designed for deep, framework-native debugging.
The Approach:
If you are already deeply embedded in the LangChain ecosystem, LangSmith feels seamless. Because LangChain manages the orchestration of your agents, it automatically logs every step of the chain into LangSmith's UI. You get a granular breakdown of latency, token usage, and step-by-step inputs and outputs.
The Drawback:
LangSmith is built for debugging, not necessarily for FinOps or budget enforcement. Furthermore, its automatic tracing heavily relies on you using the LangChain framework. As a16z noted in their analysis of emerging AI architectures, many engineering teams are actively moving away from heavy orchestration frameworks in favor of raw provider SDKs or lightweight internal wrappers to reduce overhead.
If you aren't using LangChain, relying on LangSmith requires wrapping your Python or TypeScript functions in custom @traceable decorators. It’s a heavy lift that litters your business logic with observability boilerplate.
Braintrust: The Evaluation Engine
Braintrust approaches tracing from the perspective of testing, evaluations (evals), and prompt engineering.
The Approach:
Braintrust provides excellent tooling for tracking agent memory, tool calls, and dataset evaluations. It allows AI engineers to capture complex multi-agent workflows and use those traces to create "golden datasets" for regression testing.
The Drawback:
Manual instrumentation overhead. Braintrust requires deliberate code modification. To trace an agent, your engineers must manually start and stop spans within their code. For a platform team trying to wrangle dozens of internal AI applications, enforcing this level of custom instrumentation across an entire organization is a major friction point.
Cloudidr: The FinOps-First Approach
Unlike tools built strictly for granular code debugging, Cloudidr is an AI FinOps platform built to answer the most critical platform questions: What are our agents doing, how much is it costing, and how do we enforce limits?
Cloudidr provides comprehensive agent tracing with zero manual span instrumentation.
Zero-Friction Visibility via the Proxy Layer
Cloudidr acts as an intelligent network proxy. You change your base URL, add your Cloudidr API key, and you are done. It is a 2-line integration that supports OpenAI, Anthropic, Google Gemini, and AWS Bedrock out of the box.
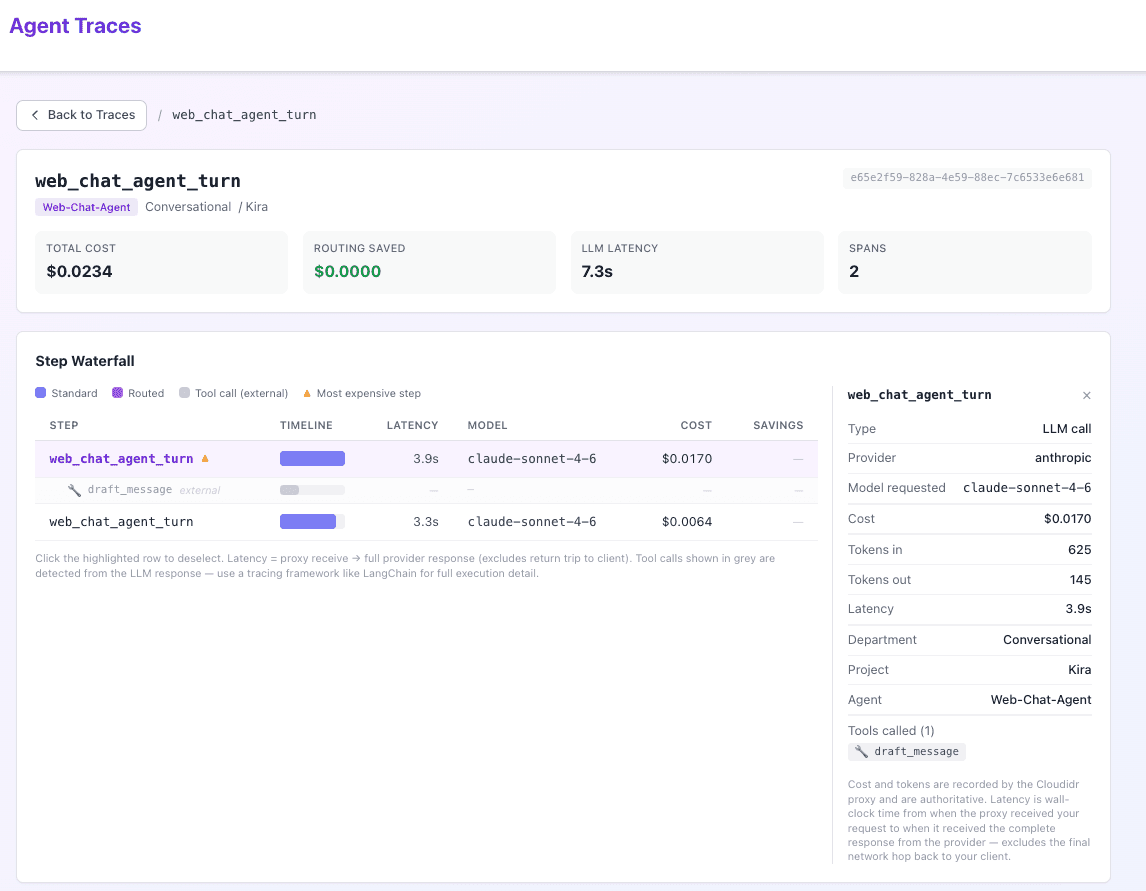
Making Sense of Multi-Step Execution
With those two lines of code, Cloudidr populates the Step Waterfall dashboard, making trace analysis effortless:
- Instant Cost & Latency: See the agent's total turn cost and end-to-end LLM latency without scraping provider billing consoles.
- Automatic Bottleneck Detection: The UI automatically flags the most expensive step in the reasoning chain, allowing for targeted optimization.
- Zero-Touch Tool Call Inference: Cloudidr detects external tool executions natively from the provider response, inserting them into the waterfall timeline—no client-side tracing frameworks required.
- Granular Attribution: Every trace is automatically enriched with metadata, mapping costs to specific Departments and Projects.
Actionable Control, Not Just Observability
Where observability tools stop at showing the trace, Cloudidr acts on it through our LLM Ops control plane:
- Enforce Hard Budgets: Assign dollar limits to individual agents. When an agent hits its cap, Cloudidr cuts it off at the proxy level.
- Intelligent Model Routing: Not every sub-task requires a frontier model. Cloudidr automatically routes requests to the cheapest capable model in real time, cutting costs by up to 90%.
- Resilience via DR Compute: By sitting at the proxy layer, Cloudidr acts as a failover mechanism, ensuring high availability even if a primary provider experiences an outage.
Which Approach Fits Your Stack?
Use LangSmith if: You are 100% committed to the LangChain ecosystem and your primary goal is deep code-level debugging.
Use Braintrust if: Your core focus is building complex evaluation pipelines and you have the bandwidth for manual instrumentation.
Use Cloudidr if: You want immediate, organization-wide visibility into AI spend, and you need to enforce hard budget caps and automate cost savings via a zero-instrumentation, 2-line integration.
Stop Paying for Agent Overhead
Tracing your AI agents shouldn’t require a dedicated engineering sprint. AI FinOps demands speed, accuracy, and automation. By moving agent tracing and cost control to the proxy layer, you free your engineers to focus on building better agents, while your finance and platform teams get the exact visibility they need.
Ready to see exactly what your agents are costing you, without rewriting your code? Cloudidr is trusted by 100+ teams to tame LLM sprawl. Explore our free starter plan today.
Autonomous AI agents are fundamentally changing the math of cloud infrastructure. A single user prompt no longer equals a single API call. Instead, agents trigger reasoning loops, execute tool calls, retrieve memory context, and retry failures. A seemingly simple user request can easily spawn a dozen distinct calls to Anthropic or OpenAI, quietly burning through your API budget.
When agent spending spirals, engineering and finance teams face a shared mandate: you need to see exactly what these models are doing under the hood. You need agent tracing.
But how you trace your agents dictates whether you solve your cost problem or just create a new integration nightmare for your platform team. The market currently offers deep observability frameworks like LangSmith, evaluation tools like Braintrust, and AI FinOps platforms like Cloudidr.
Here is how these approaches compare, and why the simplest integration often yields the highest operational ROI.
The Problem with Agent Visibility
Tracing an AI agent isn't like monitoring a standard microservice. Agents are non-deterministic. A typical agent trace must capture the initial prompt, the LLM's decision to invoke an external tool, the tool's execution, the model's subsequent reasoning, and the final user-facing response.
According to Gartner's projections on generative AI, managing the cost and complexity of these multi-step generative workflows is the primary operational hurdle for enterprise AI deployment. If you can't trace the multi-step execution tree, you can't debug model hallucinations. More importantly, you cannot attribute costs to specific teams, projects, or users.
LangChain (LangSmith): The Ecosystem Heavyweight
LangSmith, built by the creators of LangChain, is a powerful observability tool designed for deep, framework-native debugging.
The Approach:
If you are already deeply embedded in the LangChain ecosystem, LangSmith feels seamless. Because LangChain manages the orchestration of your agents, it automatically logs every step of the chain into LangSmith's UI. You get a granular breakdown of latency, token usage, and step-by-step inputs and outputs.
The Drawback:
LangSmith is built for debugging, not necessarily for FinOps or budget enforcement. Furthermore, its automatic tracing heavily relies on you using the LangChain framework. As a16z noted in their analysis of emerging AI architectures, many engineering teams are actively moving away from heavy orchestration frameworks in favor of raw provider SDKs or lightweight internal wrappers to reduce overhead.
If you aren't using LangChain, relying on LangSmith requires wrapping your Python or TypeScript functions in custom @traceable decorators. It’s a heavy lift that litters your business logic with observability boilerplate.
Braintrust: The Evaluation Engine
Braintrust approaches tracing from the perspective of testing, evaluations (evals), and prompt engineering.
The Approach:
Braintrust provides excellent tooling for tracking agent memory, tool calls, and dataset evaluations. It allows AI engineers to capture complex multi-agent workflows and use those traces to create "golden datasets" for regression testing.
The Drawback:
Manual instrumentation overhead. Braintrust requires deliberate code modification. To trace an agent, your engineers must manually start and stop spans within their code. For a platform team trying to wrangle dozens of internal AI applications, enforcing this level of custom instrumentation across an entire organization is a major friction point.
Cloudidr: The FinOps-First Approach
Unlike tools built strictly for granular code debugging, Cloudidr is an AI FinOps platform built to answer the most critical platform questions: What are our agents doing, how much is it costing, and how do we enforce limits?
Cloudidr provides comprehensive agent tracing with zero manual span instrumentation.
Zero-Friction Visibility via the Proxy Layer
Cloudidr acts as an intelligent network proxy. You change your base URL, add your Cloudidr API key, and you are done. It is a 2-line integration that supports OpenAI, Anthropic, Google Gemini, and AWS Bedrock out of the box.
Making Sense of Multi-Step Execution
With those two lines of code, Cloudidr populates the Step Waterfall dashboard, making trace analysis effortless:
- Instant Cost & Latency: See the agent's total turn cost and end-to-end LLM latency without scraping provider billing consoles.
- Automatic Bottleneck Detection: The UI automatically flags the most expensive step in the reasoning chain, allowing for targeted optimization.
- Zero-Touch Tool Call Inference: Cloudidr detects external tool executions natively from the provider response, inserting them into the waterfall timeline—no client-side tracing frameworks required.
- Granular Attribution: Every trace is automatically enriched with metadata, mapping costs to specific Departments and Projects.
Actionable Control, Not Just Observability
Where observability tools stop at showing the trace, Cloudidr acts on it through our LLM Ops control plane:
- Enforce Hard Budgets: Assign dollar limits to individual agents. When an agent hits its cap, Cloudidr cuts it off at the proxy level.
- Intelligent Model Routing: Not every sub-task requires a frontier model. Cloudidr automatically routes requests to the cheapest capable model in real time, cutting costs by up to 90%.
- Resilience via DR Compute: By sitting at the proxy layer, Cloudidr acts as a failover mechanism, ensuring high availability even if a primary provider experiences an outage.
Which Approach Fits Your Stack?
Use LangSmith if: You are 100% committed to the LangChain ecosystem and your primary goal is deep code-level debugging.
Use Braintrust if: Your core focus is building complex evaluation pipelines and you have the bandwidth for manual instrumentation.
Use Cloudidr if: You want immediate, organization-wide visibility into AI spend, and you need to enforce hard budget caps and automate cost savings via a zero-instrumentation, 2-line integration.
Stop Paying for Agent Overhead
Tracing your AI agents shouldn’t require a dedicated engineering sprint. AI FinOps demands speed, accuracy, and automation. By moving agent tracing and cost control to the proxy layer, you free your engineers to focus on building better agents, while your finance and platform teams get the exact visibility they need.
Ready to see exactly what your agents are costing you, without rewriting your code? Cloudidr is trusted by 100+ teams to tame LLM sprawl. Explore our free starter plan today.
Explore More from Cloudidr ...
Explore More from Cloudidr ...
Explore More from Cloudidr ...
Explore More from Cloudidr ...

Enterprise AI Gateway: Full-Stack VPC Deployment — Your Data Never Leaves Your AWS Account
Enterprise AI Gateway: Full-Stack VPC Deployment — Your Data Never Leaves Your AWS Account

How We Slashed Inference Costs by 80% with Managed Gemma 4 31B
How We Slashed Inference Costs by 80% with Managed Gemma 4 31B

The LLM API Tax — How Cloudidr's Developer-Lite AI FinOps Quickly Fixes LLM Spend
The LLM API Tax — How Cloudidr's Developer-Lite AI FinOps Quickly Fixes LLM Spend
Load More
Load More


Backed by

Backed by
Backed by